|
I am currently a postdoctoral fellow in the Department of EECS at University of California, Berkeley, affiliated with Berkeley Artificial Intelligence Research Lab (BAIR) and Berkeley Deep Drive (BDD) , supervised by Prof. Kurt Keutzer . Prior to that, I received my Ph.D degree from the Department of Automation at Tsinghua University, advised by Prof. Jie Zhou and Prof. Jiwen Lu. In 2018, I received my BS degree from the Department of Physics, Tsinghua University. I am generally interested in artificial intelligence and deep learning. My current research focuses on: 🦙 Large Models + 🚙 Embodied Agents -> 🤖 AGI Email / CV / Google Scholar / GitHub |

|
|
|
|
*Equal contribution †Project leader/Corresponding author. |
|
|
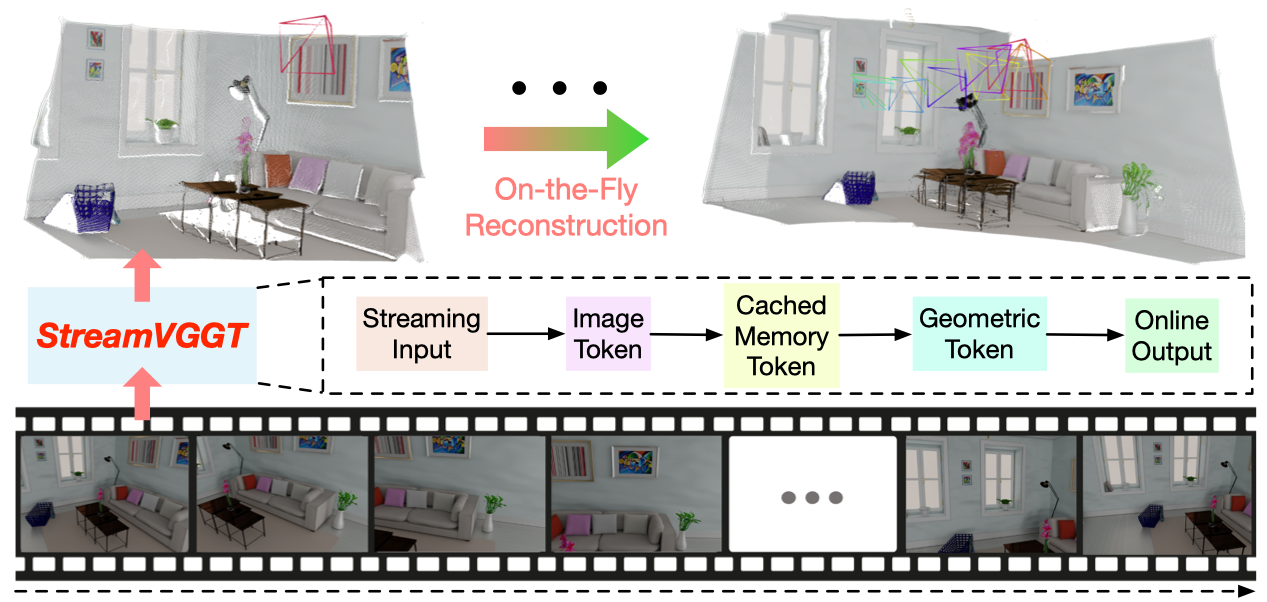
|
Dong Zhuo*, Wenzhao Zheng*†, Jiahe Guo, Yuqi Wu, Jie Zhou, Jiwen Lu arXiv, 2025. [arXiv] [Code] [Project Page] StreamVGGT employs temporal causal attention and leverages cached token memory to support efficient incremental on-the-fly reconstruction, enabling interative and real-time online applications. |
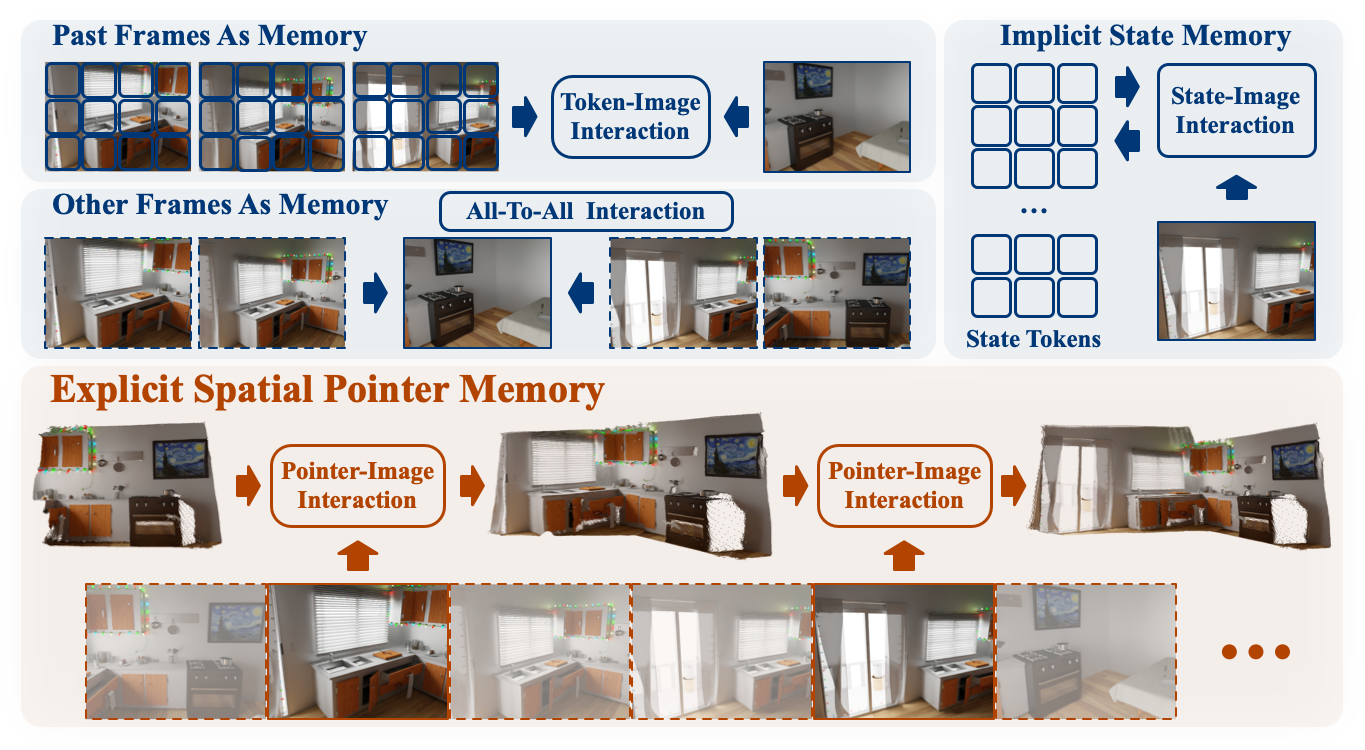
|
Yuqi Wu*, Wenzhao Zheng*†, Jie Zhou, Jiwen Lu arXiv, 2025. [arXiv] [Code] [Project Page] Point3R is an online framework for dense streaming 3D reconstruction using explicit spatial memory, which achieves competitive performance with low training costs. |

|
Weiliang Chen, Wenzhao Zheng†, Yu Zheng, Lei Chen, Jie Zhou, Jiwen Lu, Yueqi Duan arXiv, 2025. [arXiv] [Code] [Project Page] GenWorld features three key characteristics: 1) Real-world Simulation, 2) High Quality, and 3) Cross-prompt Diversity, which can serve as a foundation for AI-generated video detection research with practical significance. |
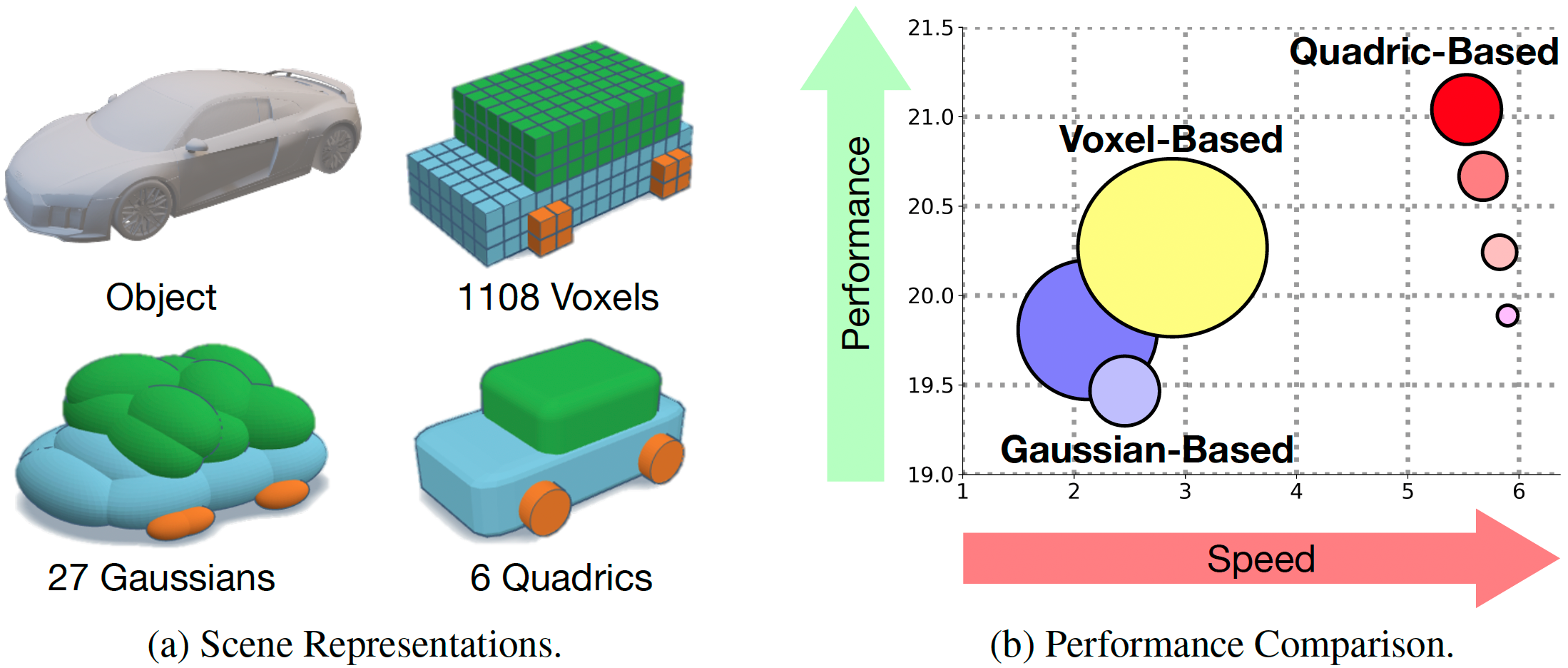
|
Sicheng Zuo*, Wenzhao Zheng*†, Xiaoyong Han*, Longchao Yang, Yong Pan, Jiwen Lu arXiv, 2025. [arXiv] [Code] QuadricFormer proposes geometrically expressive superquadrics as scene primitives, enabling efficient and powerful object-centric representation of driving scenes. |

|
Weiliang Chen, Jiayi Bi, Yuanhui Huang, Wenzhao Zheng†, Yueqi Duan arXiv, 2025. [arXiv] [Code] [Project Page] SceneCompleter explores 3D scene completion for generative novel view synthesis by jointly modeling geometry and appearance. |
|
|

|
Yuanhui Huang , Wenzhao Zheng†, Yuan Gao, Xin Tao, Pengfei Wan, Di Zhang, Jie Zhou, Jiwen Lu arXiv, 2024. [arXiv] [Code] [中文解读 (in Chinese)] Owl-1 approaches consistent long video generation with an omni world model, which models the evolution of the underlying world with latent state, explicit observation and world dynamics variables. |

|
Anthony Chen*, Wenzhao Zheng*†, Yida Wang*, Xueyang Zhang, Kun Zhan, Peng Jia, Kurt Keutzer, Shanghang Zhang arXiv, 2025. [arXiv] [Code] [Project Page] [中文解读 (in Chinese)] GeoDrive integrates robust 3D conditions into driving world models, enhancing spatial understanding and action controllability. |
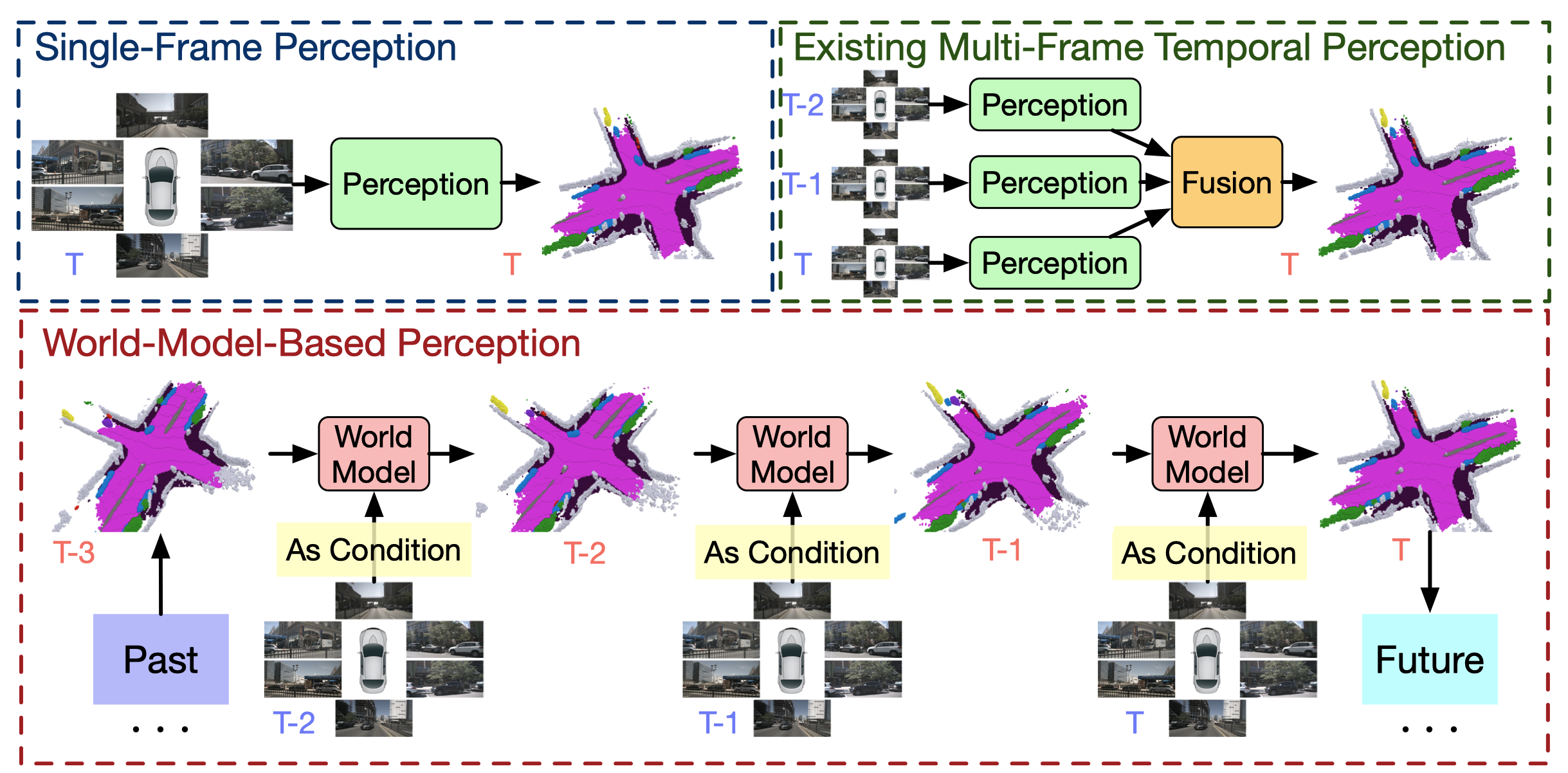
|
Sicheng Zuo*, Wenzhao Zheng*†, Yuanhui Huang, Jie Zhou, Jiwen Lu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. [arXiv] [Code] [中文解读 (in Chinese)] GaussianWorld reformulates 3D occupancy prediction as a 4D occupancy forecasting problem conditioned on the current sensor input and propose a Gaussian World Model to exploit the scene evolution for perception. |
|
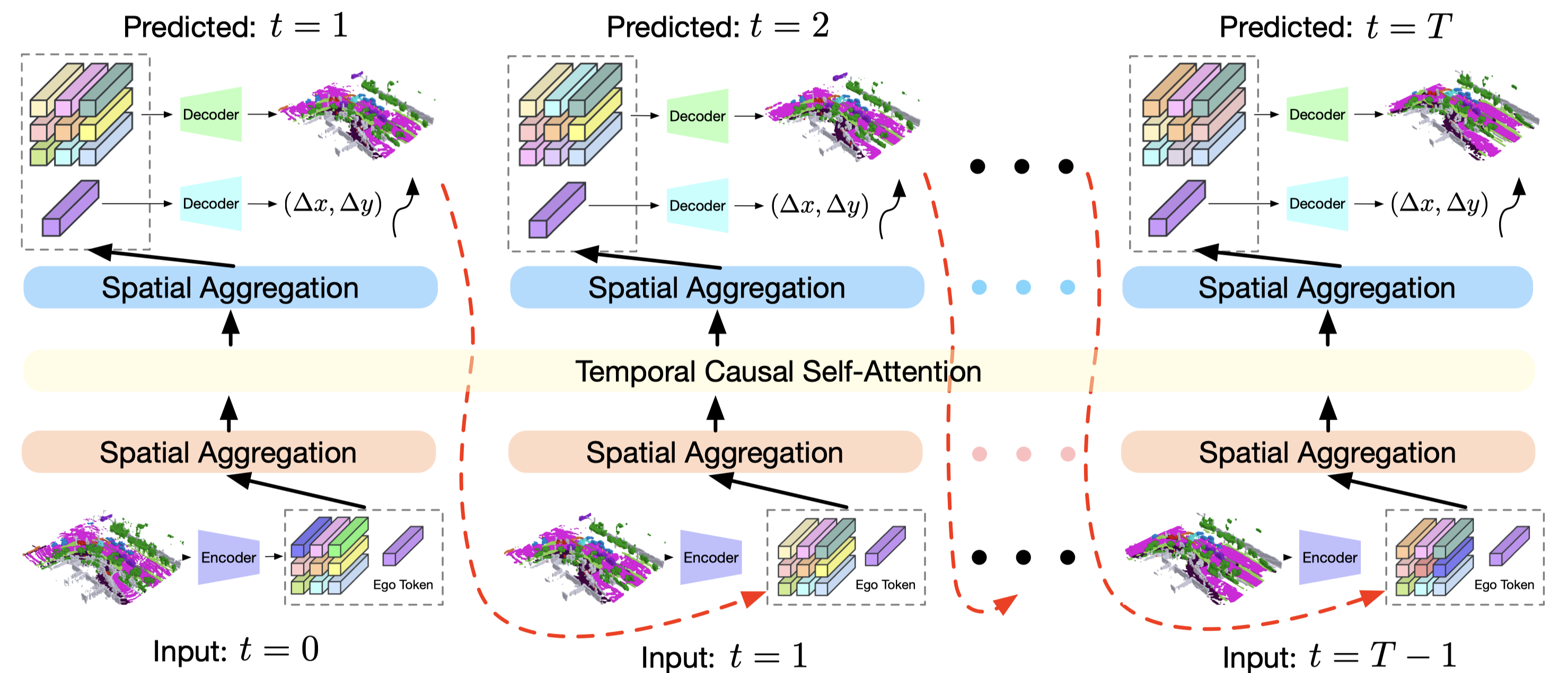
Wenzhao Zheng*†, Weiliang Chen*, Yuanhui Huang, Borui Zhang, Yueqi Duan, Jiwen Lu European Conference on Computer Vision (ECCV), 2024. [arXiv] [Code] [Project Page] [中文解读 (in Chinese)] OccWorld models the joint evolutions of 3D scenes and ego movements and paves the way for interpretable end-to-end large driving models. |
|
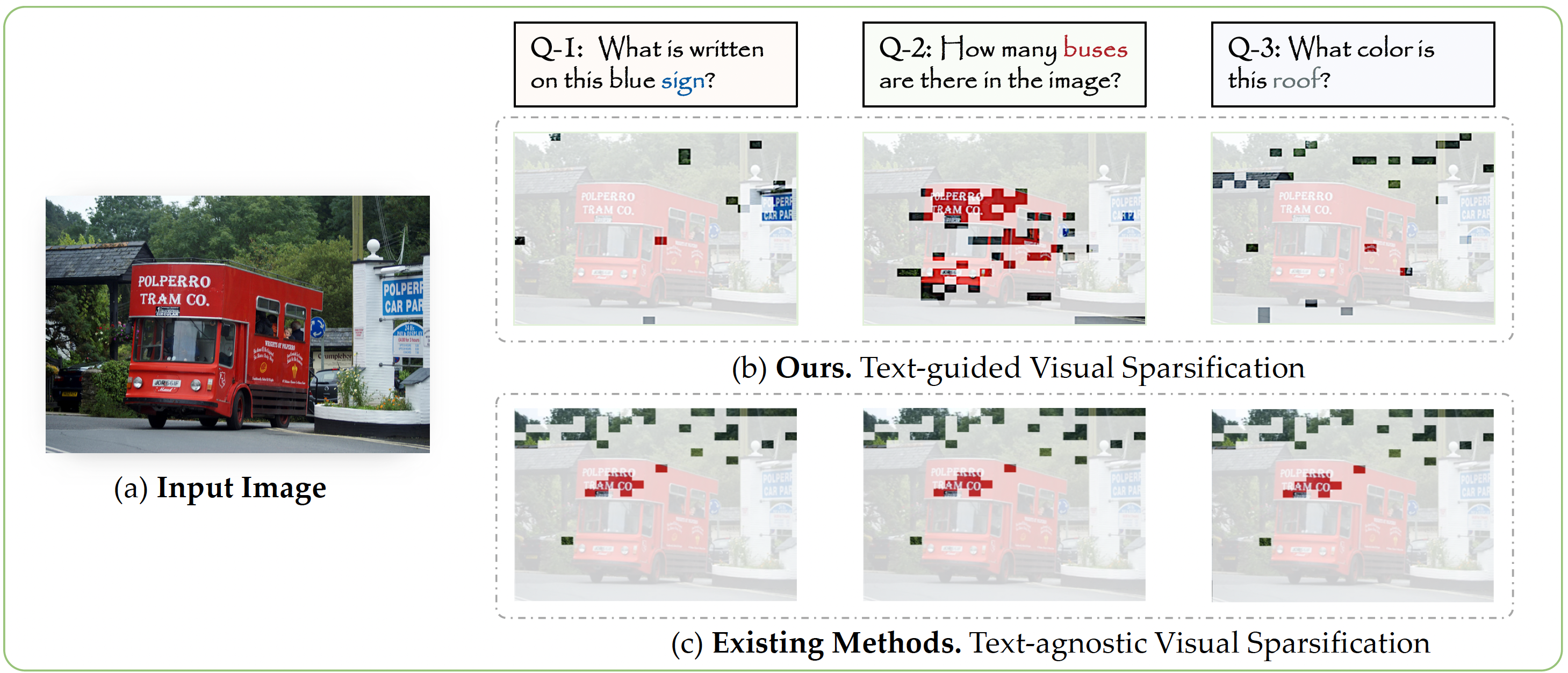
Yuan Zhang*, Chun-Kai Fan*, Junpeng Ma*, Wenzhao Zheng†, Tao Huang, Kuan Cheng, Denis Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, Shanghang Zhang International Conference on Machine Learning (ICML), 2025. [arXiv] [Code] [Project Page] SparseVLM sparsifies visual tokens adaptively based on the question prompt. |

|
Nan Huang, Wenzhao Zheng, Chenfeng Xu , Kurt Keutzer , Shanghang Zhang, Angjoo Kanazawa, Qianqian Wang IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. [arXiv] [Code] [Project Page] Our model produces instance-level fine-grained moving object masks and can handle challenging scenarios including articulated structures, shadow reflections, dynamic background motion, and drastic camera movement. |
|
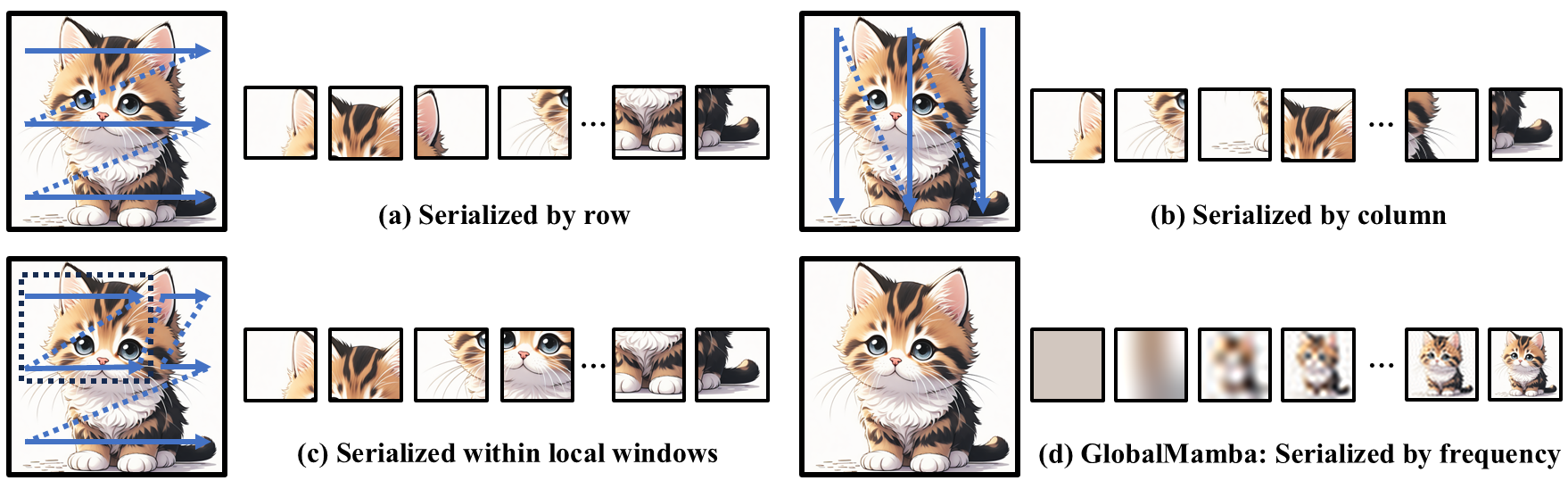
Chengkun Wang*, Wenzhao Zheng*†, Jie Zhou, Jiwen Lu arXiv, 2024. [arXiv] [Code] GlobalMamba constructs a causal token sequence by frequency, while ensuring that tokens acquire global feature information. |
|
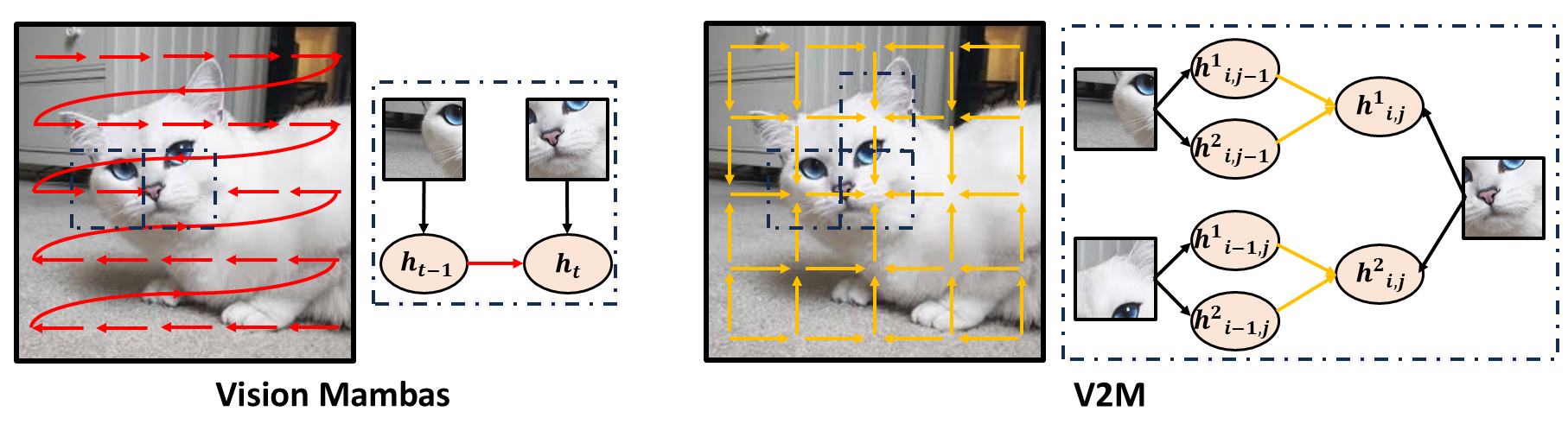
Chengkun Wang*, Wenzhao Zheng*†, Yuanhui Huang, Jie Zhou, Jiwen Lu arXiv, 2024. [arXiv] [Code] Visual 2-Dimensional Mamba (V2M) generalize SSM to the 2-dimensional space and generates the next state considering two adjacent states on both dimensions (e.g., columns and rows) which directly processes image tokens in the 2D space. |

|
Yuanhui Huang, Weiliang Chen, Wenzhao Zheng†, Yueqi Duan, Jie Zhou, Jiwen Lu IEEE International Conference on Computer Vision (ICCV), 2025. [arXiv] [Code] [Project Page] We propose a Spectral AutoRegressive (SpectralAR) visual generation framework to achieve causality for visual sequences from the spectral perspective. |

|
Jiajun Dong*, Chengkun Wang*, Wenzhao Zheng†, Lei Chen, Jiwen Lu, Yansong Tang arXiv, 2025. [arXiv] [Code] [中文解读 (in Chinese)] GaussianToken represents each image by a set of 2D Gaussian tokens in a feed-forward manner. |

|
Wenzhao Zheng*†, Zetian Xia*, Yuanhui Huang , Sicheng Zuo, Jie Zhou, Jiwen Lu arXiv, 2024. [arXiv] [Code] [Project Page] [中文解读 (in Chinese)] Doe-1 is the first closed-loop autonomous driving model for unified perception, prediction, and planning. |
|
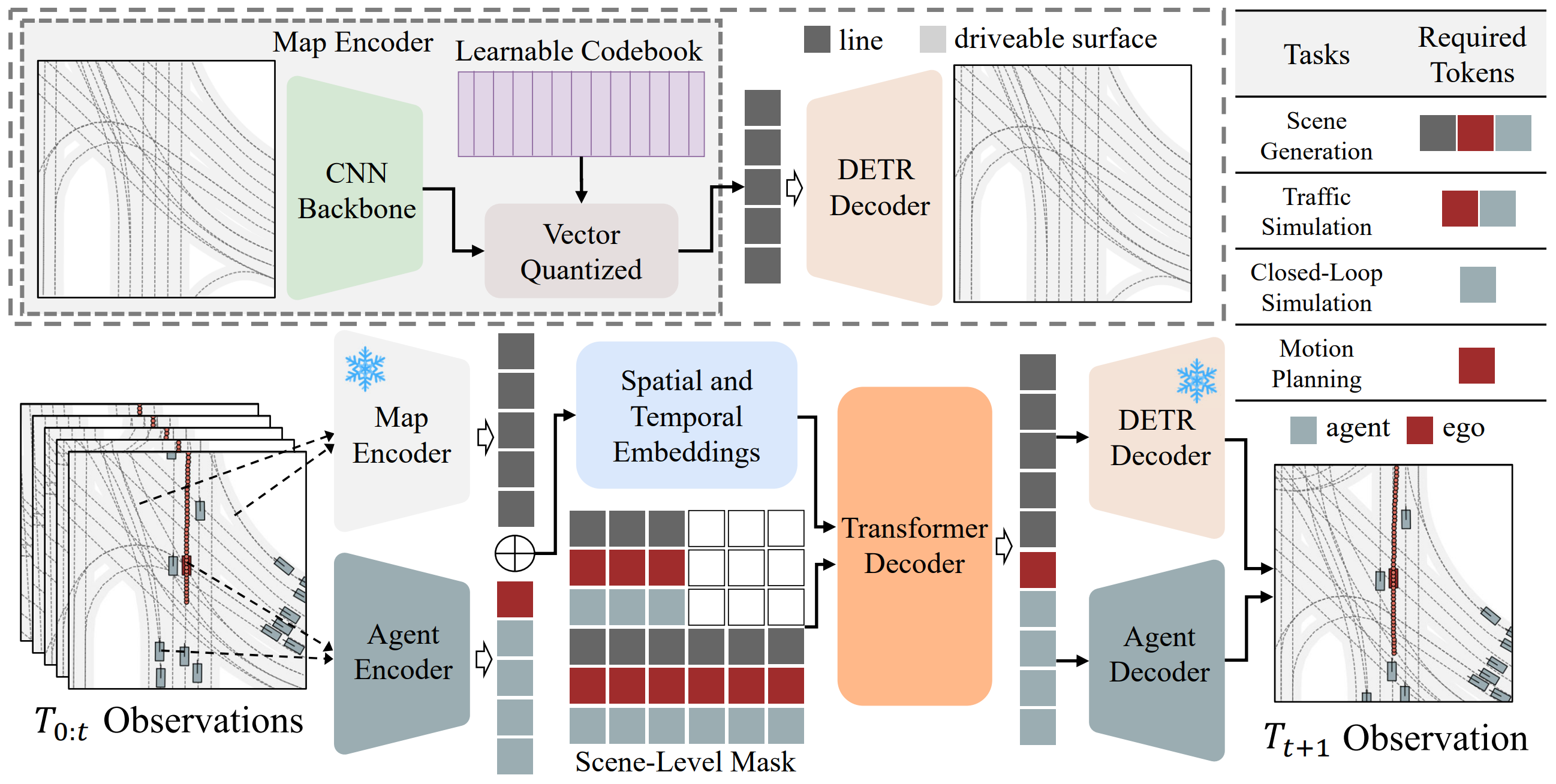
Zetian Xia*, Sicheng Zuo*, Wenzhao Zheng*†, Yunpeng Zhang, Dalong Du, Jie Zhou, Jiwen Lu, Shanghang Zhang arXiv, 2024. [arXiv] [Code] [Project Page] [中文解读 (in Chinese)] GPD-1 proposes a unified approach that seamlessly accomplishes multiple aspects of scene evolution, including scene simulation, traffic simulation, closed-loop simulation, map prediction, and motion planning, all without additional fine-tuning. |

|
Lening Wang* , Wenzhao Zheng*†, Dalong Du, Yunpeng Zhang, Yilong Ren , Han Jiang , Zhiyong Cui , Haiyang Yu , Jie Zhou, Jiwen Lu, Shanghang Zhang IEEE International Conference on Computer Vision (ICCV), 2025. [arXiv] [Code] [Project Page] Spatial-Temporal simulAtion for drivinG (Stag-1) enables controllable 4D autonomous driving simulation with spatial-temporal decoupling. |
|
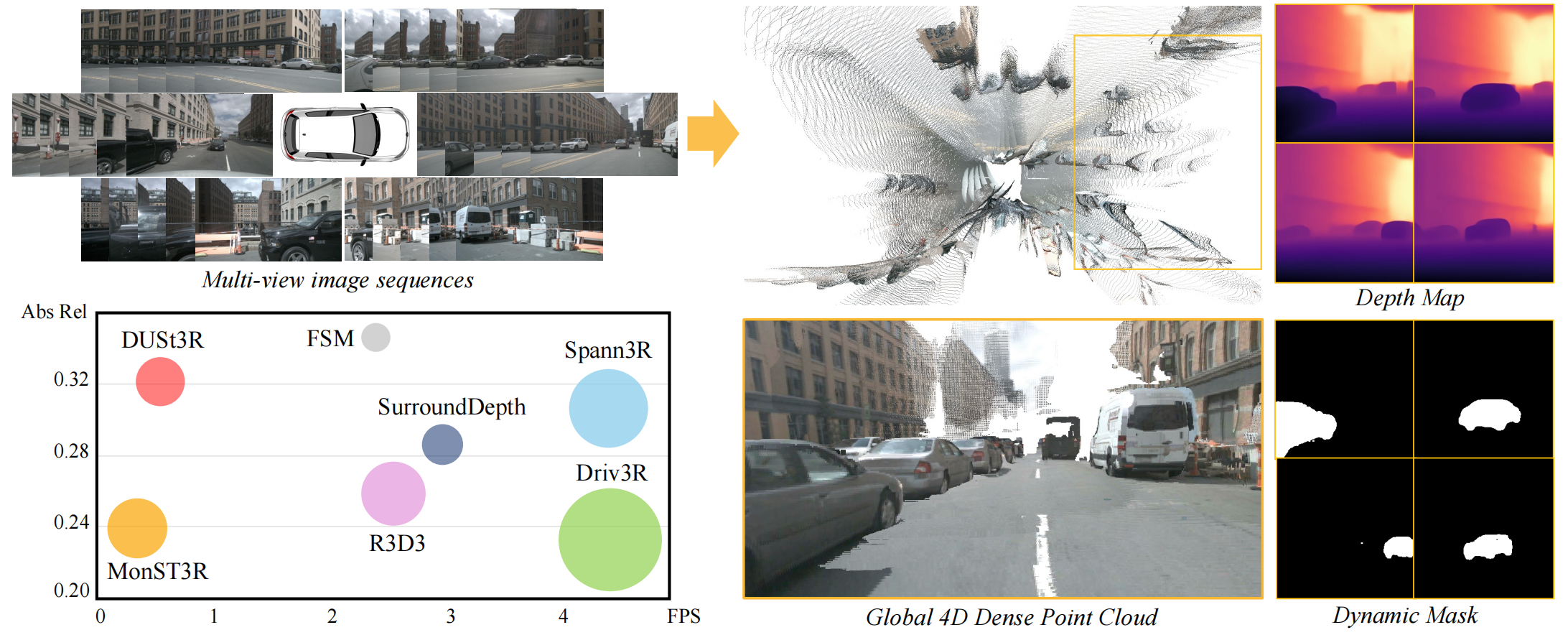
Xin Fei , Wenzhao Zheng†, Yueqi Duan, Wei Zhan , Masayoshi Tomizuka , Kurt Keutzer , Jiwen Lu arXiv, 2024. [arXiv] [Code] [Project Page] Driv3R predicts per-frame pointmaps in the global consistent coordinate system in an optimization-free manner. |
|
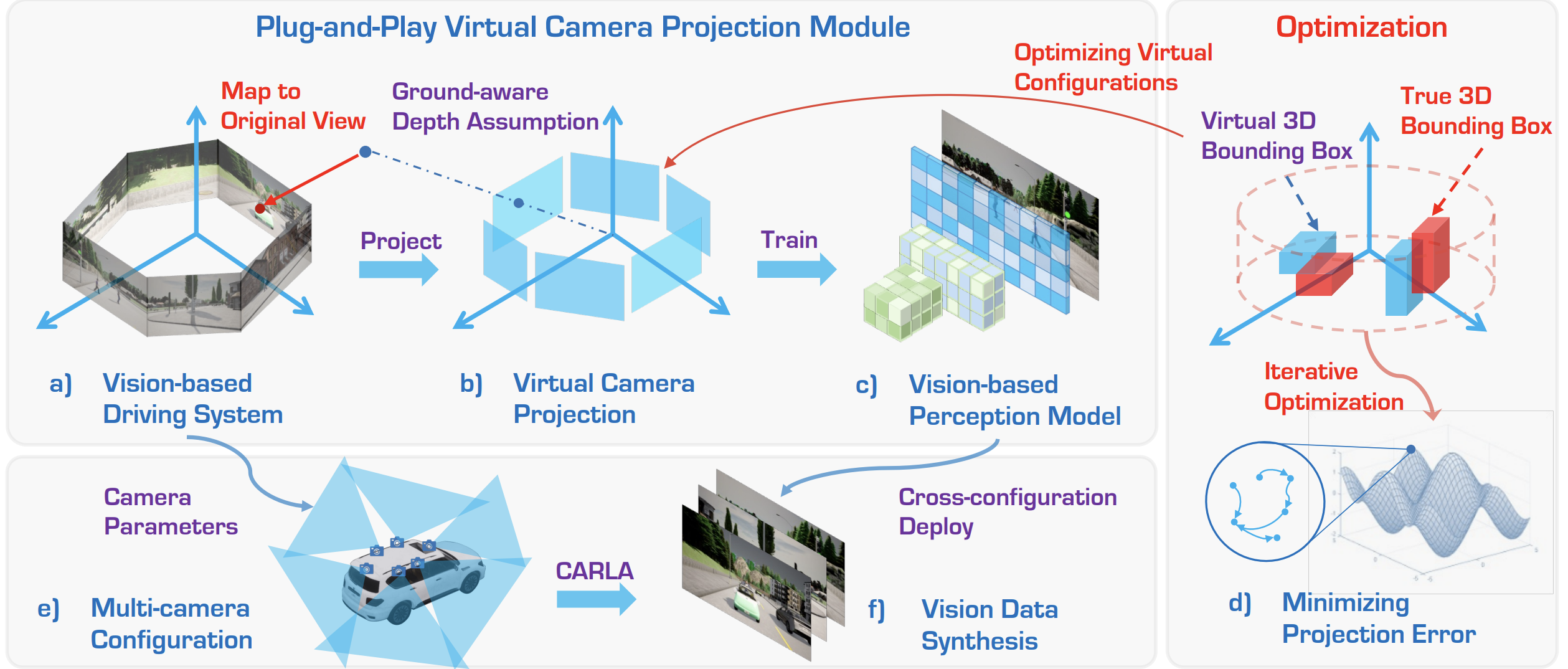
Ye Li, Wenzhao Zheng†, Xiaonan Huang , Kurt Keutzer International Conference on Learning Representations (ICLR), 2025. [arXiv] [Code] [Project Page] [中文解读 (in Chinese)] UniDrive presents the first comprehensive framework designed to generalize vision-centric 3D perception models across diverse camera configurations. |
|
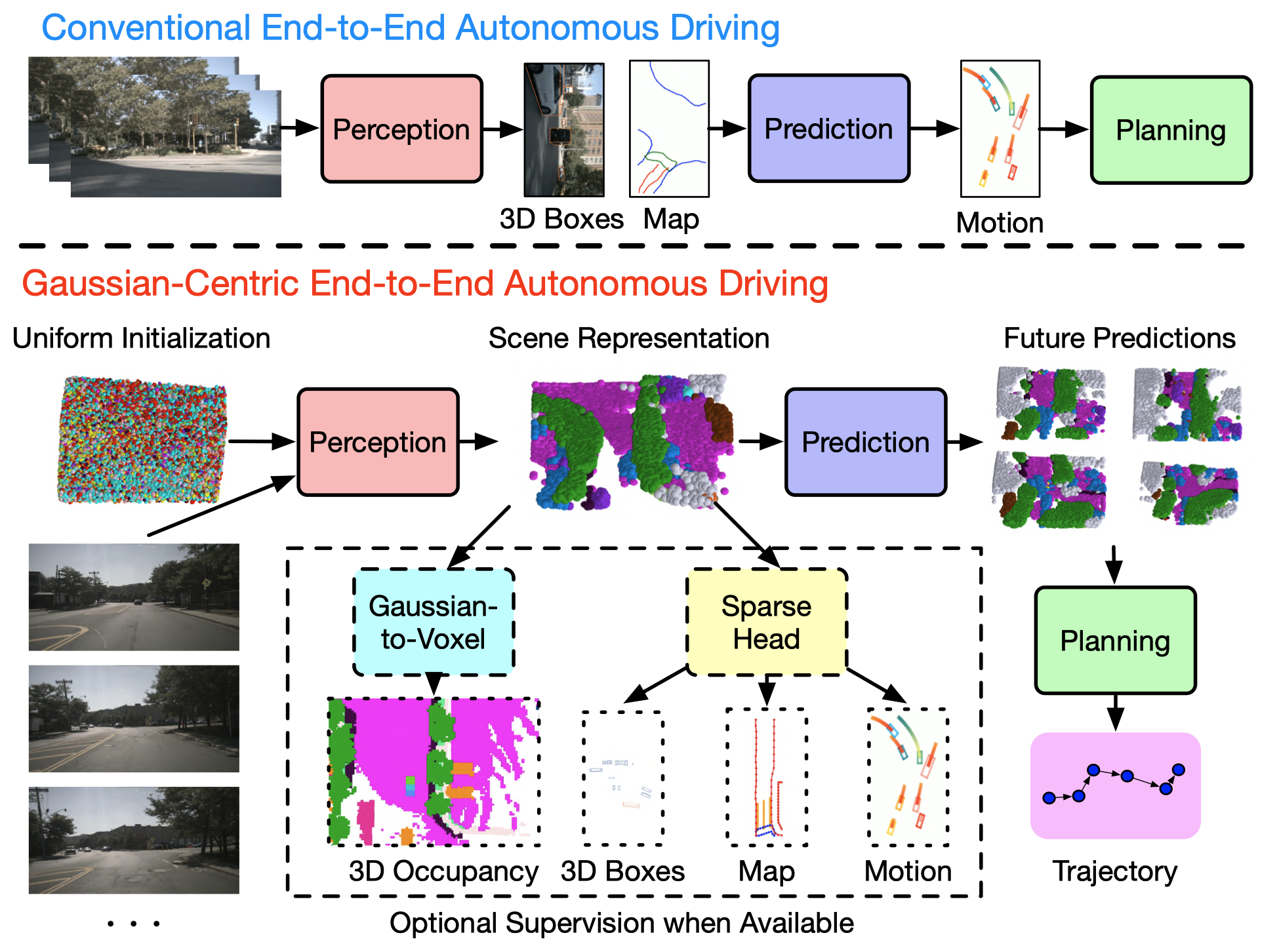
Wenzhao Zheng*†, Junjie Wu*, Yao Zheng*, Sicheng Zuo, Zixun Xie, Longchao Yang, Yong Pan, Zhihui Hao, Peng Jia, Xianpeng Lang, Shanghang Zhang arXiv, 2024. [arXiv] [Code] [中文解读 (in Chinese)] GaussianAD is a Gaussian-centric end-to-end framework which employs sparse yet comprehensive 3D Gaussians to pass information through the pipeline to efficiently preserve more details. |
|
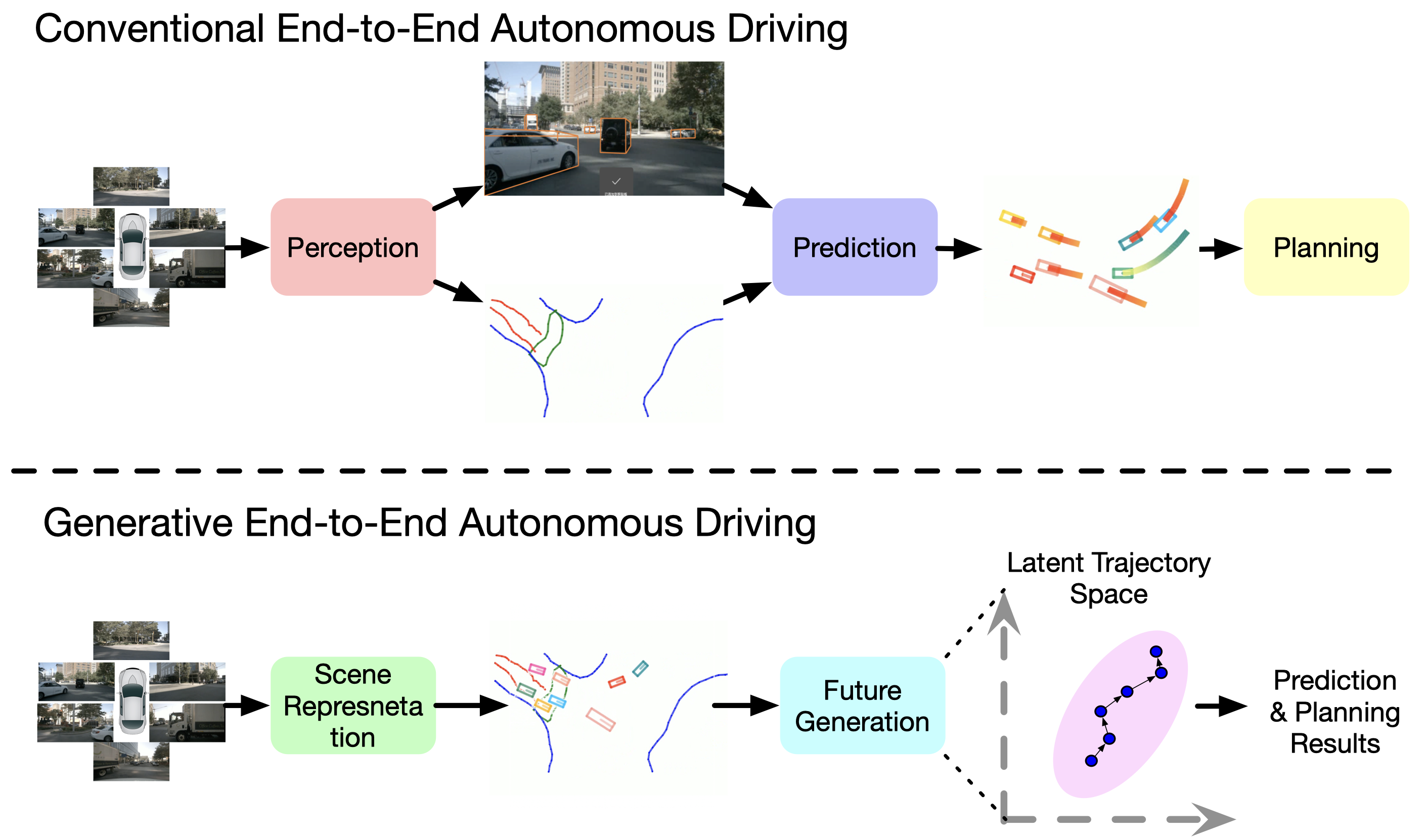
Wenzhao Zheng*, Ruiqi Song* , Xianda Guo* , Chenming Zhang , Long Chen European Conference on Computer Vision (ECCV), 2024. [arXiv] [Code] [中文解读 (in Chinese)] GenAD casts end-to-end autonomous driving as a generative modeling problem. |
|
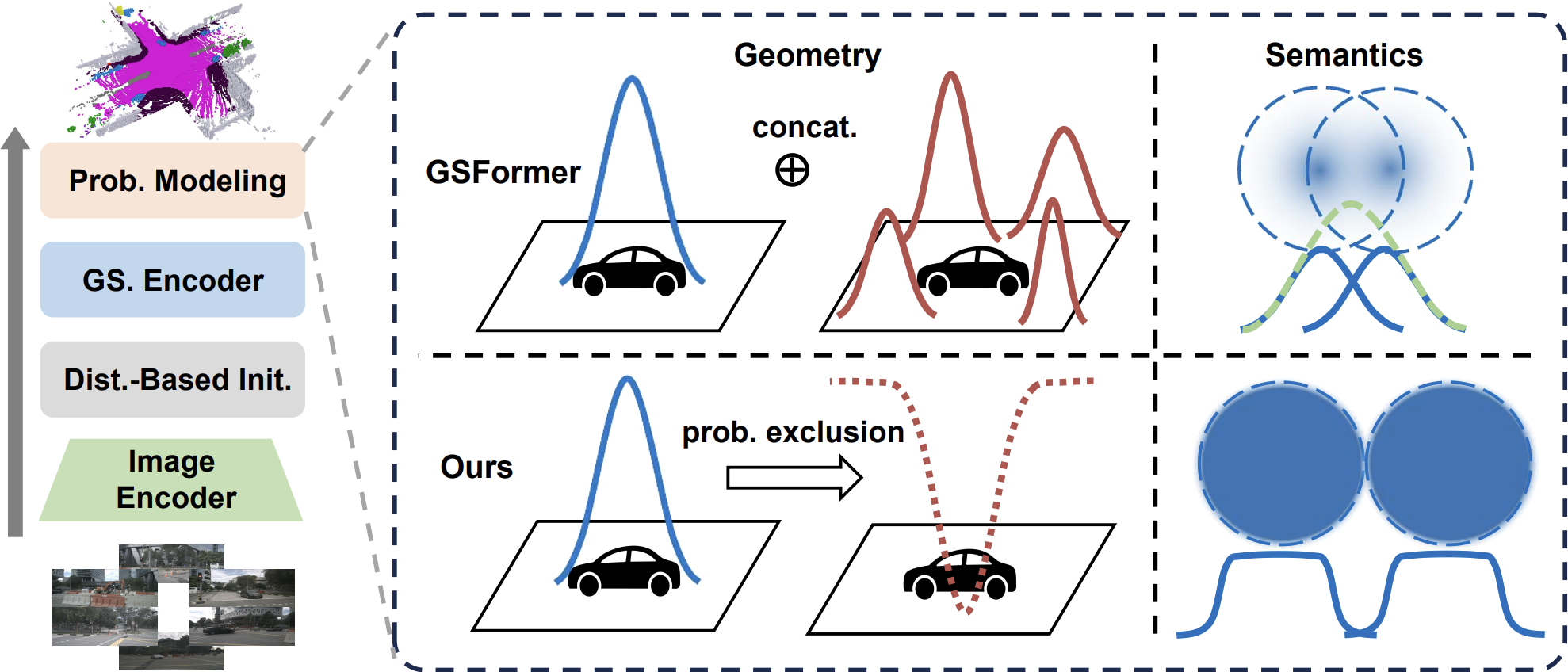
Yuanhui Huang, Amonnut Thammatadatrakoon, Wenzhao Zheng†, Yunpeng Zhang, Dalong Du, Jiwen Lu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. [arXiv] [Code] [Project Page] GaussianFormer-2 interprets each Gaussian as a probability distribution of its neighborhood being occupied and conforms to probabilistic multiplication to derive the overall geometry. |
|
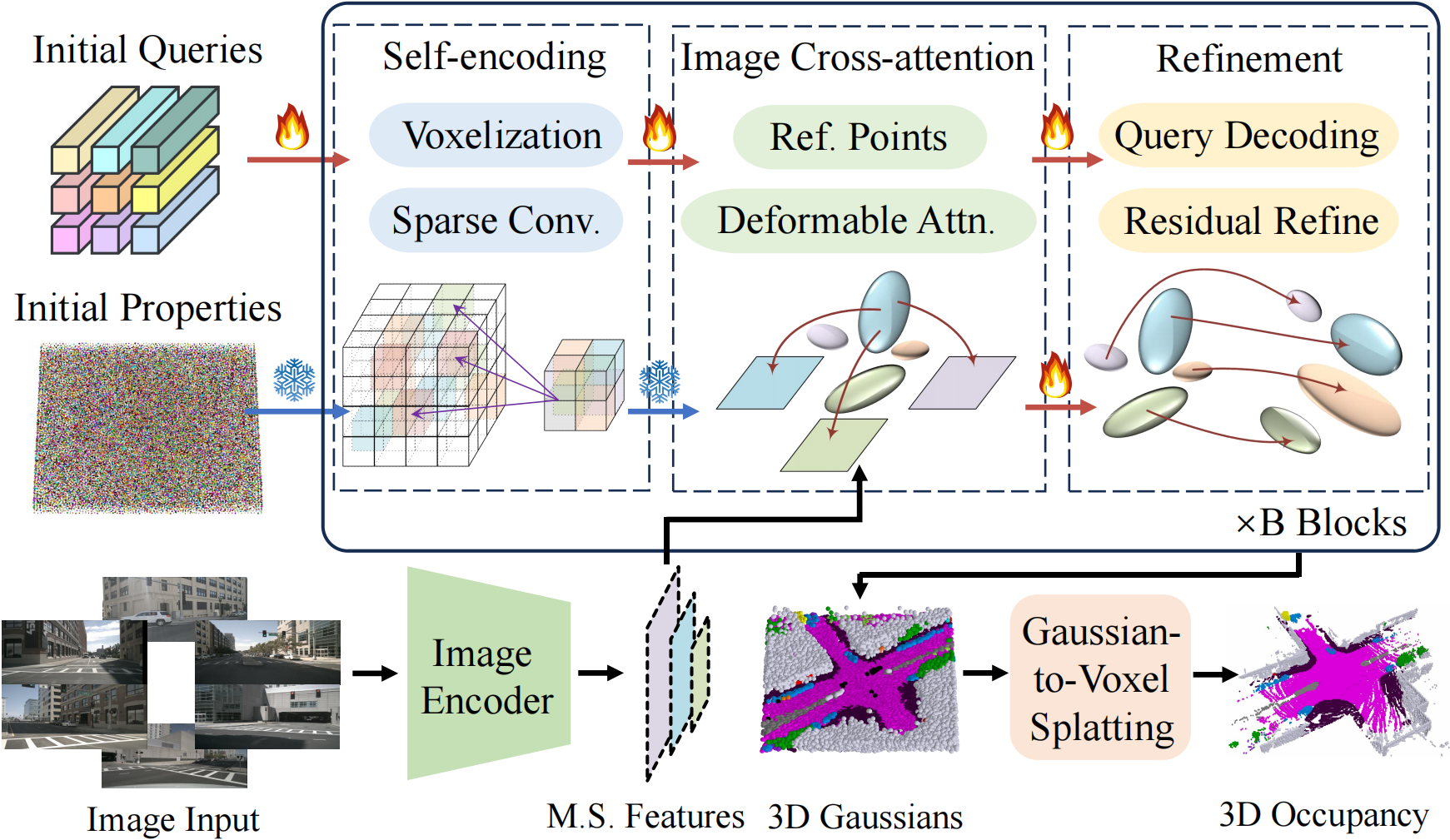
Yuanhui Huang , Wenzhao Zheng†, Yunpeng Zhang , Jie Zhou, Jiwen Lu European Conference on Computer Vision (ECCV), 2024. [arXiv] [Code] [Project Page] [中文解读 (in Chinese)] GaussianFormer proposes the 3D semantic Gaussians as a more efficient object-centric representation for driving scenes compared with 3D occupancy. |
|
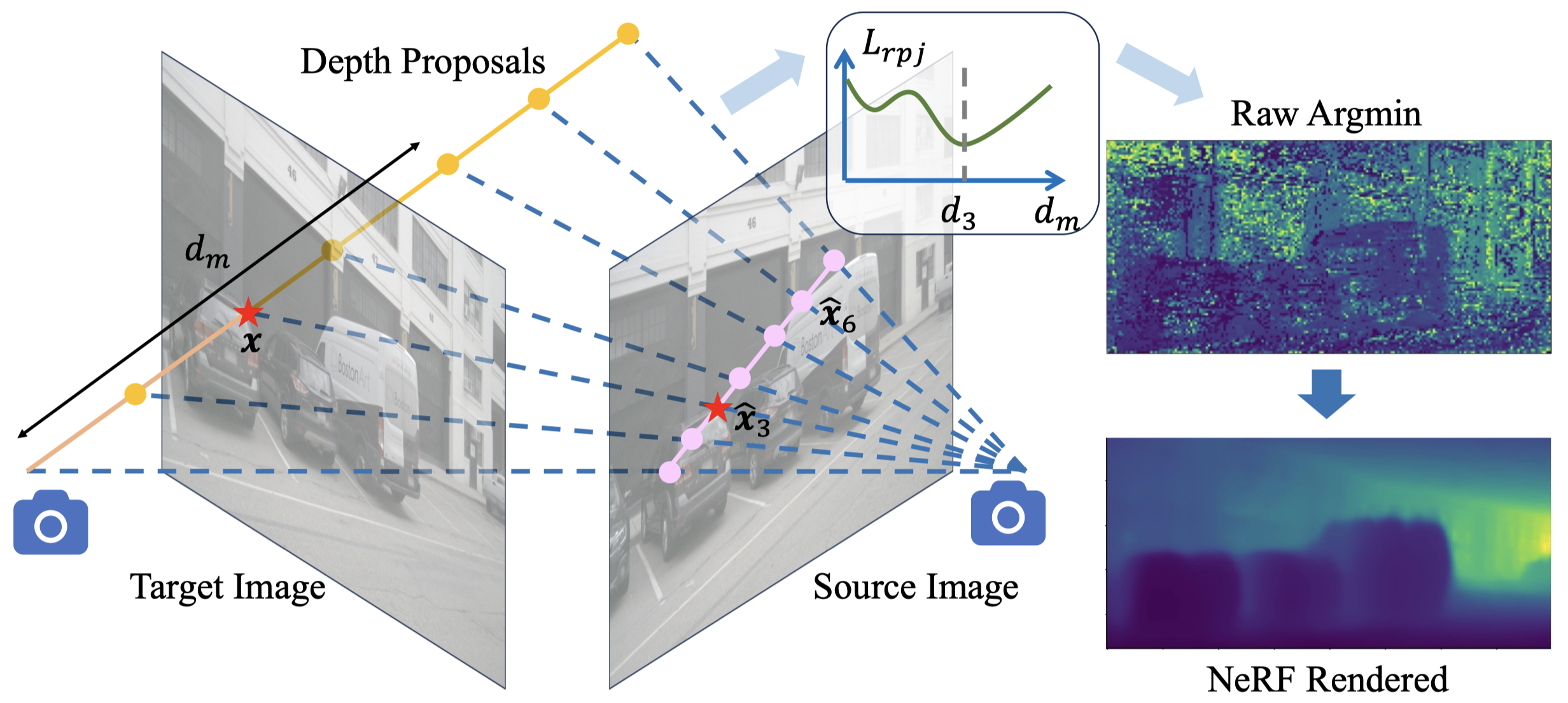
Yuanhui Huang* , Wenzhao Zheng*†, Borui Zhang , Jie Zhou, Jiwen Lu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. [arXiv] [Code] [Project Page] [中文解读 (in Chinese)] SelfOcc is the first self-supervised work that produces reasonable 3D occupancy for surround cameras. |

|
Yuanhui Huang* , Wenzhao Zheng*†, Yunpeng Zhang , Jie Zhou, Jiwen Lu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023. [arXiv] [Code] [Project Page] [中文解读 (in Chinese)] Given only surround-camera motorcycle RGB images barrier as inputs, our model (trained using trailer only sparse traffic cone LiDAR point supervision) can predict the semantic occupancy for all volumes in the 3D space. |
|
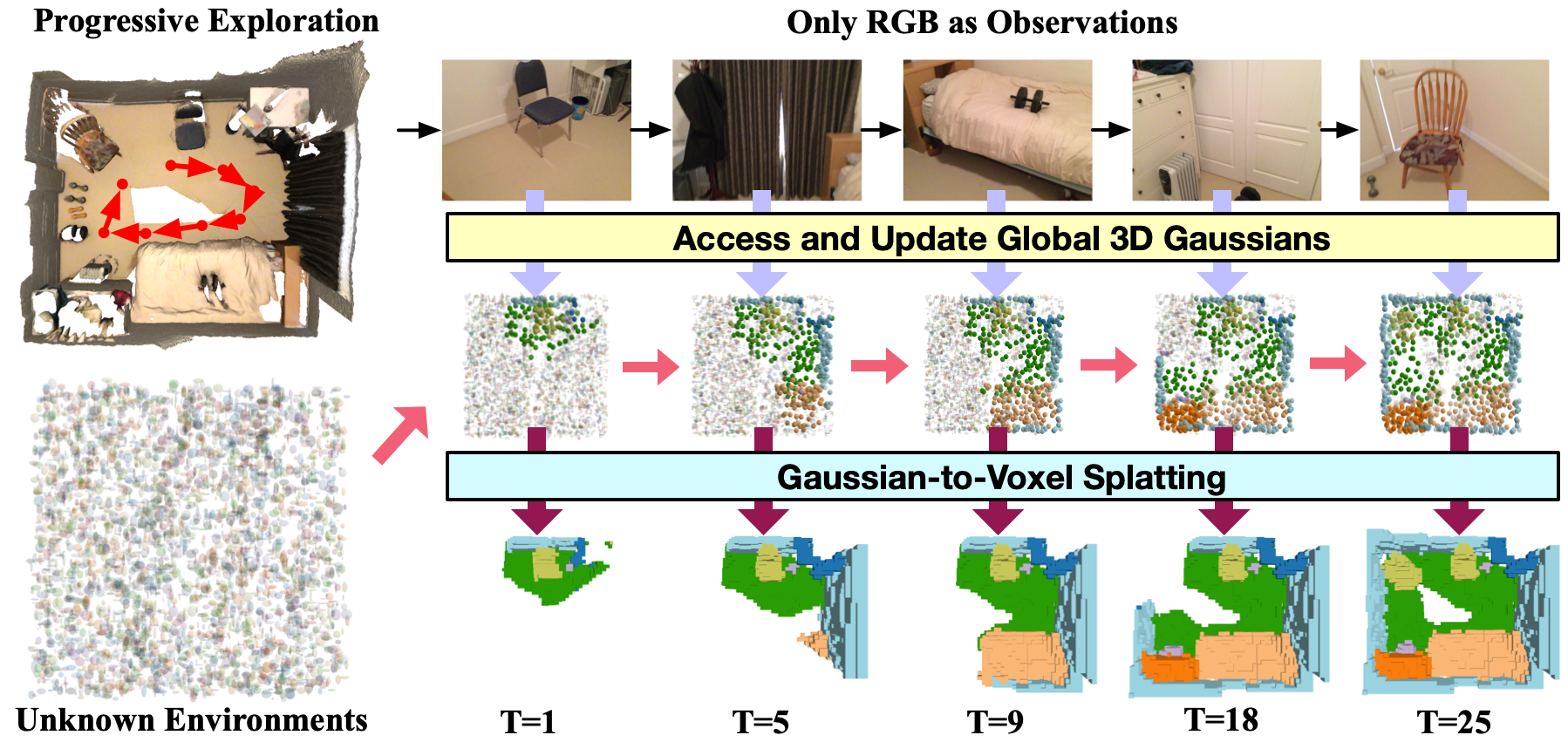
Yuqi Wu*, Wenzhao Zheng*†, Sicheng Zuo, Yuanhui Huang , Jie Zhou, Jiwen Lu IEEE International Conference on Computer Vision (ICCV), 2025. [arXiv] [Code] [Project Page] EmbodiedOcc formulates an embodied 3D occupancy prediction task and employs a Gaussian-based framework to accomplish it. |
|
|
Xin Fei , Wenzhao Zheng†, Yueqi Duan, Wei Zhan , Masayoshi Tomizuka , Kurt Keutzer , Jiwen Lu arXiv, 2024. [arXiv] [Code] [Project Page] PixelGaussian dynamically adjusts the Gaussian distributions based on geometric complexity in a feed-forward framework. |
|
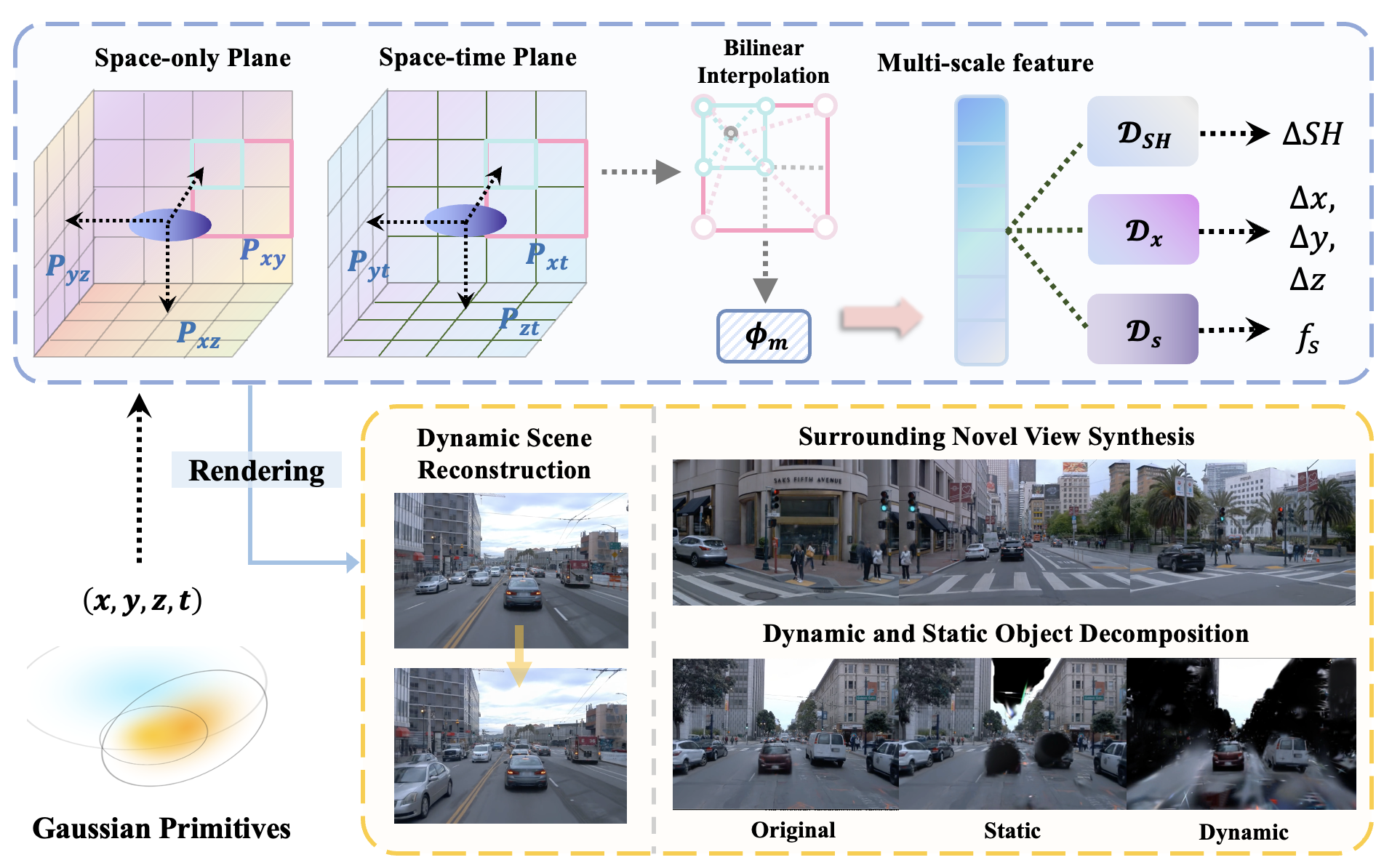
Nan Huang , Xiaobao Wei , Wenzhao Zheng†, Pengju An , Ming Lu , Wei Zhan , Masayoshi Tomizuka , Kurt Keutzer , Shanghang Zhang arXiv, 2024. [arXiv] [Code] [Project Page] S3Gaussian employs 3D Gaussians to model dynamic scenes for autonomous driving without other supervisions (e.g., 3D bounding boxes). |
|
|
|
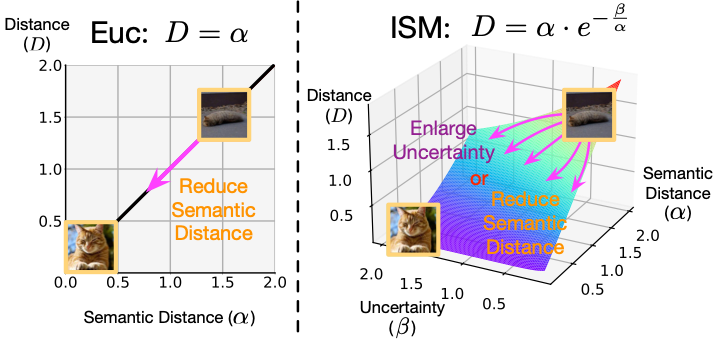
Chengkun Wang* , Wenzhao Zheng*†, Zheng Zhu, Jie Zhou, Jiwen Lu IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI, IF: 24.31), 2024. [arXiv] [Code] We propose an introspective deep metric learning (IDML) framework for uncertainty-aware comparisons of images. |
|
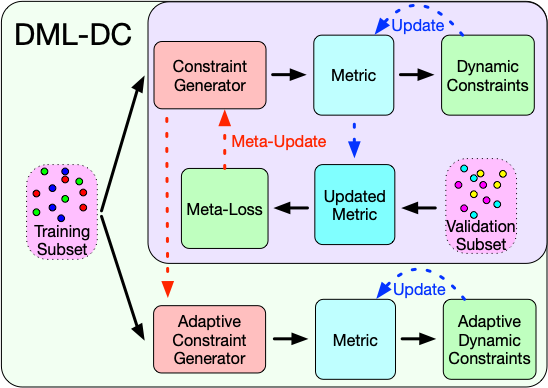
Wenzhao Zheng, Jiwen Lu, Jie Zhou IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI, IF: 24.31), 2023. [PDF] This paper formulates deep metric learning under a unified framework and propose a dynamic constraint generator to produce adaptive composite constraints to train the metric towards good generalization. |
|
Wenzhao Zheng, Zhaodong Chen , Jiwen Lu, Jie Zhou IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019 (oral). Wenzhao Zheng, Jiwen Lu, Jie Zhou IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI, IF: 24.31), 2021. [PDF] [PDF] (Journal version) [Code] We perform linear interpolation on embeddings to adaptively manipulate their hardness levels and generate corresponding label-preserving synthetics for recycled training. |
|
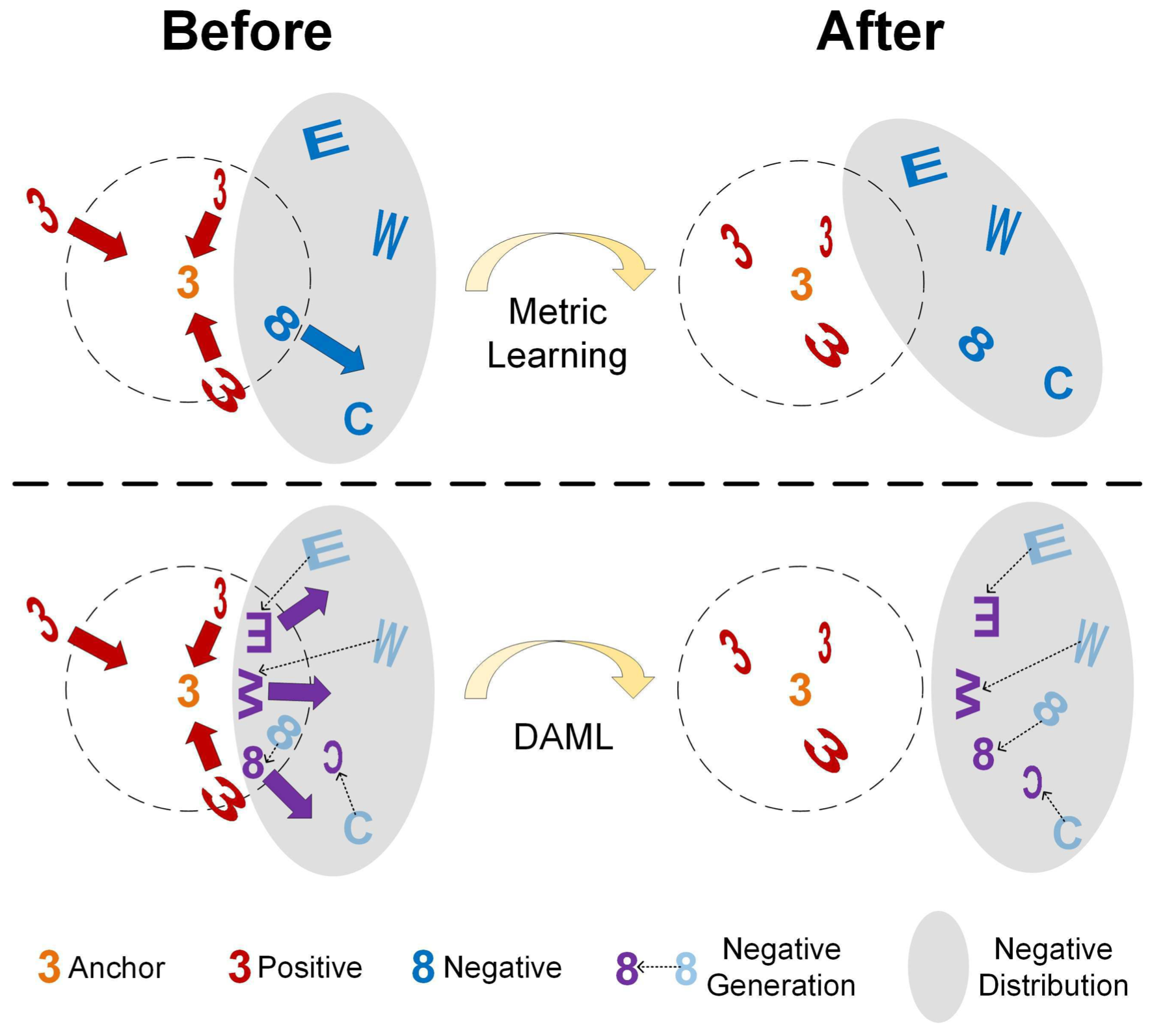
Yueqi Duan, Wenzhao Zheng, Xudong Lin , Jiwen Lu, Jie Zhou IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018 (spotlight). Yueqi Duan, Jiwen Lu, Wenzhao Zheng, Jie Zhou IEEE Transactions on Image Processing (T-IP, IF: 11.041), 2020. [PDF] [PDF] (Journal version) [Code] We generate potential hard negatives adversarial to the learned metric as complements. |
|
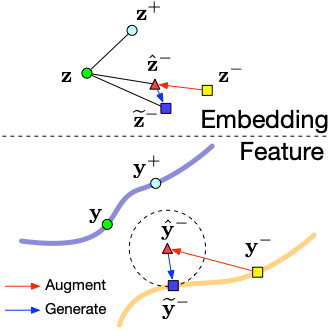
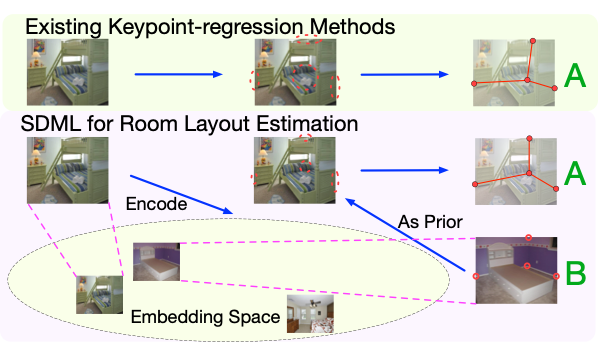
Wenzhao Zheng, Jiwen Lu Jie Zhou European Conference on Computer Vision (ECCV), 2020. [PDF] We are the first to apply deep metric learning to prediction tasks with structured labels. |
|
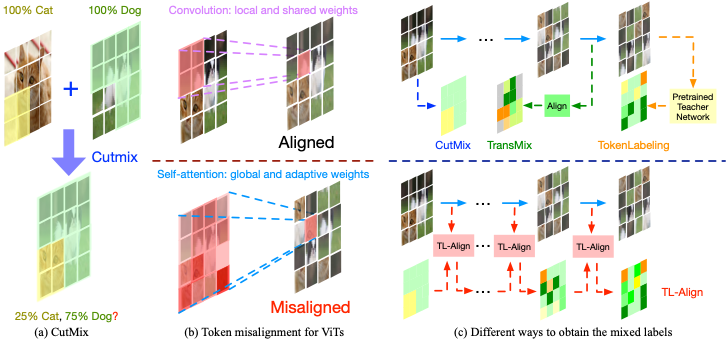
Han Xiao*, Wenzhao Zheng*, Sicheng Zuo, Peng Gao, Jie Zhou, Jiwen Lu European Conference on Computer Vision (ECCV), 2024. [PDF] We identify a token fluctuation phenomenon that has suppressed the potential of data mixing strategies for vision transformers. To adress this, we propose a token-label alignment (TL-Align) method to trace the correspondence between transformed tokens and the original tokens to maintain a label for each token. |
|
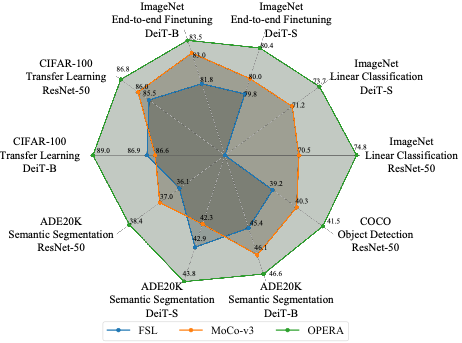
Chengkun Wang* , Wenzhao Zheng*, Zheng Zhu, Jie Zhou, Jiwen Lu IEEE International Conference on Computer Vision (ICCV), 2023. [arXiv] [Code] We unify fully supervised and self-supervised contrastive learning and exploit both supervisions from labeled and unlabeled data for training. |
|
Han Xiao*, Wenzhao Zheng*, Zheng Zhu, Jie Zhou, Jiwen Lu IEEE International Conference on Computer Vision (ICCV), 2023. [arXiv] [Code] We identify a token fluctuation phenomenon that has suppressed the potential of data mixing strategies for vision transformers. To adress this, we propose a token-label alignment (TL-Align) method to trace the correspondence between transformed tokens and the original tokens to maintain a label for each token. |
|
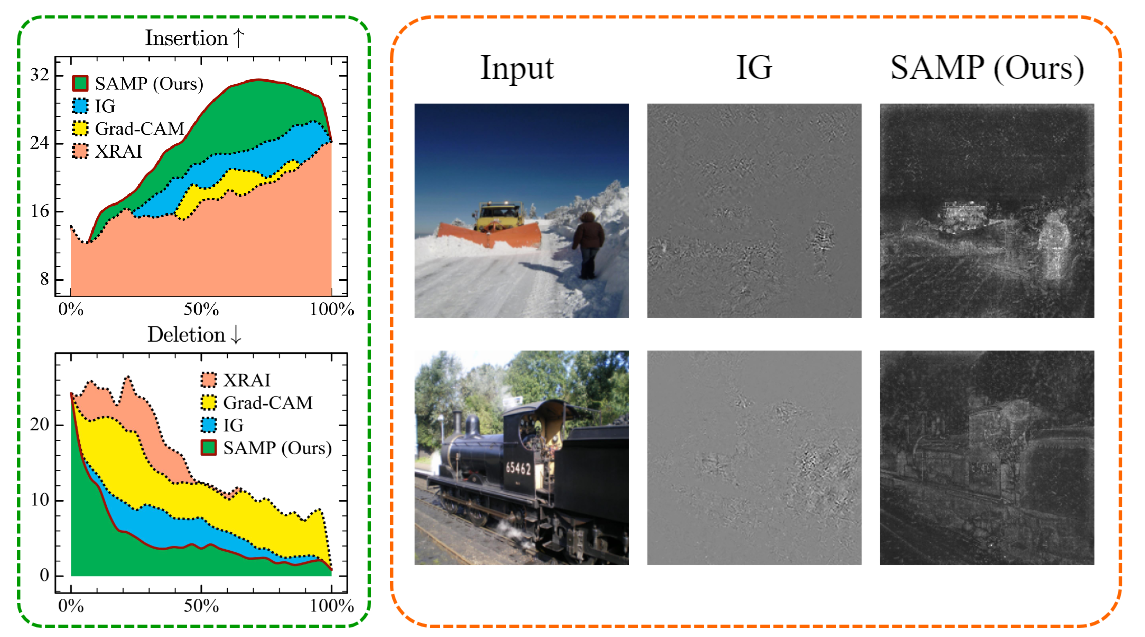
Borui Zhang, Wenzhao Zheng, Jie Zhou, Jiwen Lu International Conference on Learning Representations (ICLR), 2024. [arXiv] [Code] To address the ambiguity in attributions caused by different path choices, we introduced the Concentration Principle and developed SAMP, an efficient model-agnostic interpreter. By incorporating the infinitesimal constraint (IC) and momentum strategy (MS), SAMP provides superior interpretations. |

|
Borui Zhang, Wenzhao Zheng, Jie Zhou, Jiwen Lu International Conference on Learning Representations (ICLR), 2023. [arXiv] [Code] This paper proposes Bort, an optimizer for improving model explainability with boundedness and orthogonality constraints on model parameters, derived from the sufficient conditions of model comprehensibility and transparency. |
|
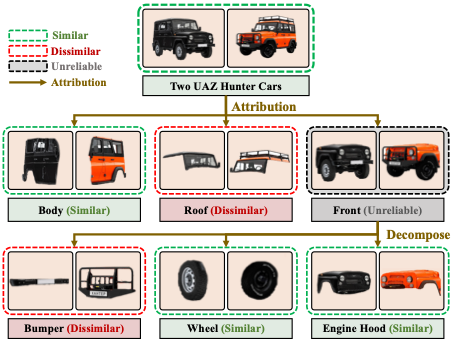
Borui Zhang, Wenzhao Zheng, Jie Zhou, Jiwen Lu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. [arXiv] [Code] This paper proposes an attributable visual similarity learning (AVSL) framework, which employs a generalized similarity learning paradigm to represent the similarity between two images with a graph for a more accurate and explainable similarity measure between images. |
|
|
|
|
|
|