|
I am currently a postdoctoral fellow in the Department of EECS at University of California, Berkeley, affiliated with Berkeley Artificial Intelligence Research Lab (BAIR) and Berkeley Deep Drive (BDD) , supervised by Prof. Kurt Keutzer . Prior to that, I received my Ph.D degree from the Department of Automation at Tsinghua University, advised by Prof. Jie Zhou and Prof. Jiwen Lu. In 2018, I received my BS degree from the Department of Physics, Tsinghua University. I am generally interested in artificial intelligence and deep learning. My current research focuses on: 🦙 Foudation Models + 🚙 Physical Intelligence -> 🤖 AGI Email / CV / Google Scholar / GitHub |

|
|
|
|
*Equal contribution †Project leader/Corresponding author. |
|
|
|
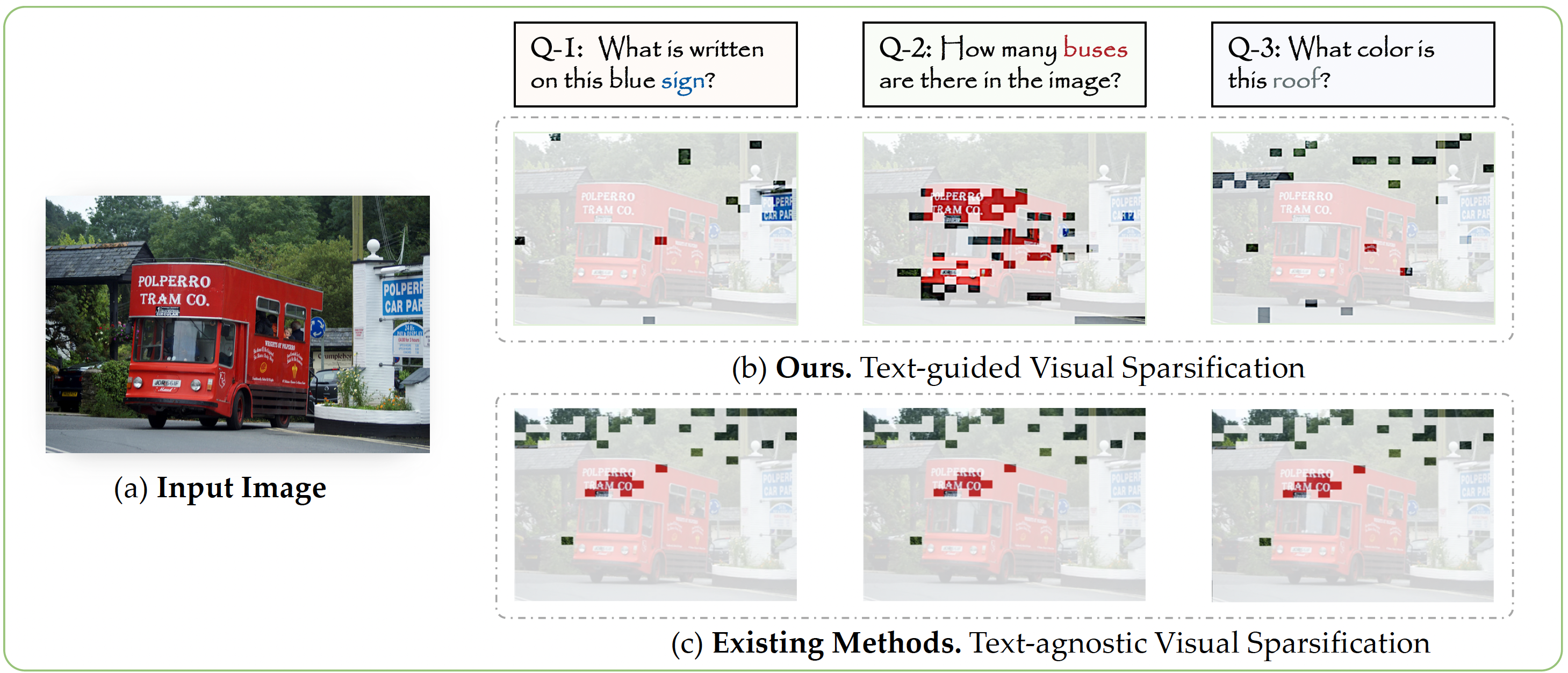
Yuan Zhang*, Chun-Kai Fan*, Junpeng Ma*, Wenzhao Zheng†, Tao Huang, Kuan Cheng, Denis Gudovskiy, Tomoyuki Okuno, Yohei Nakata, Kurt Keutzer, Shanghang Zhang International Conference on Machine Learning (ICML), 2025. [arXiv] [Code] [Project Page] SparseVLM sparsifies visual tokens adaptively based on the question prompt. |
|
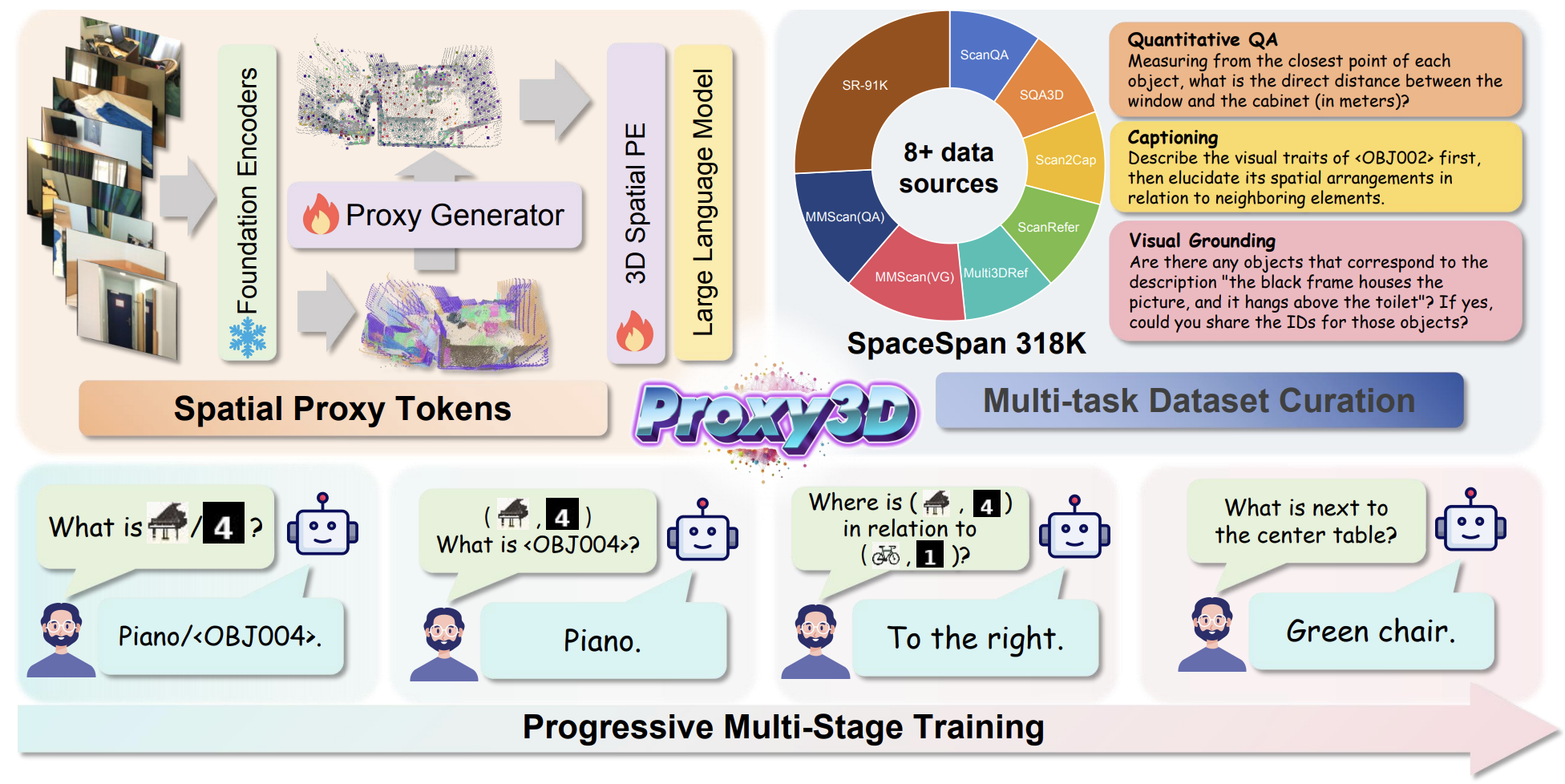
Jerry Jiang*, Haowen Sun*, Denis Gudovskiy, Yohei Nakata, Tomoyuki Okuno, Kurt Keutzer, Wenzhao Zheng† IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026. Proxy3D enalbe existing vision-language models to process 3D representations for better spatial understanding. |
|
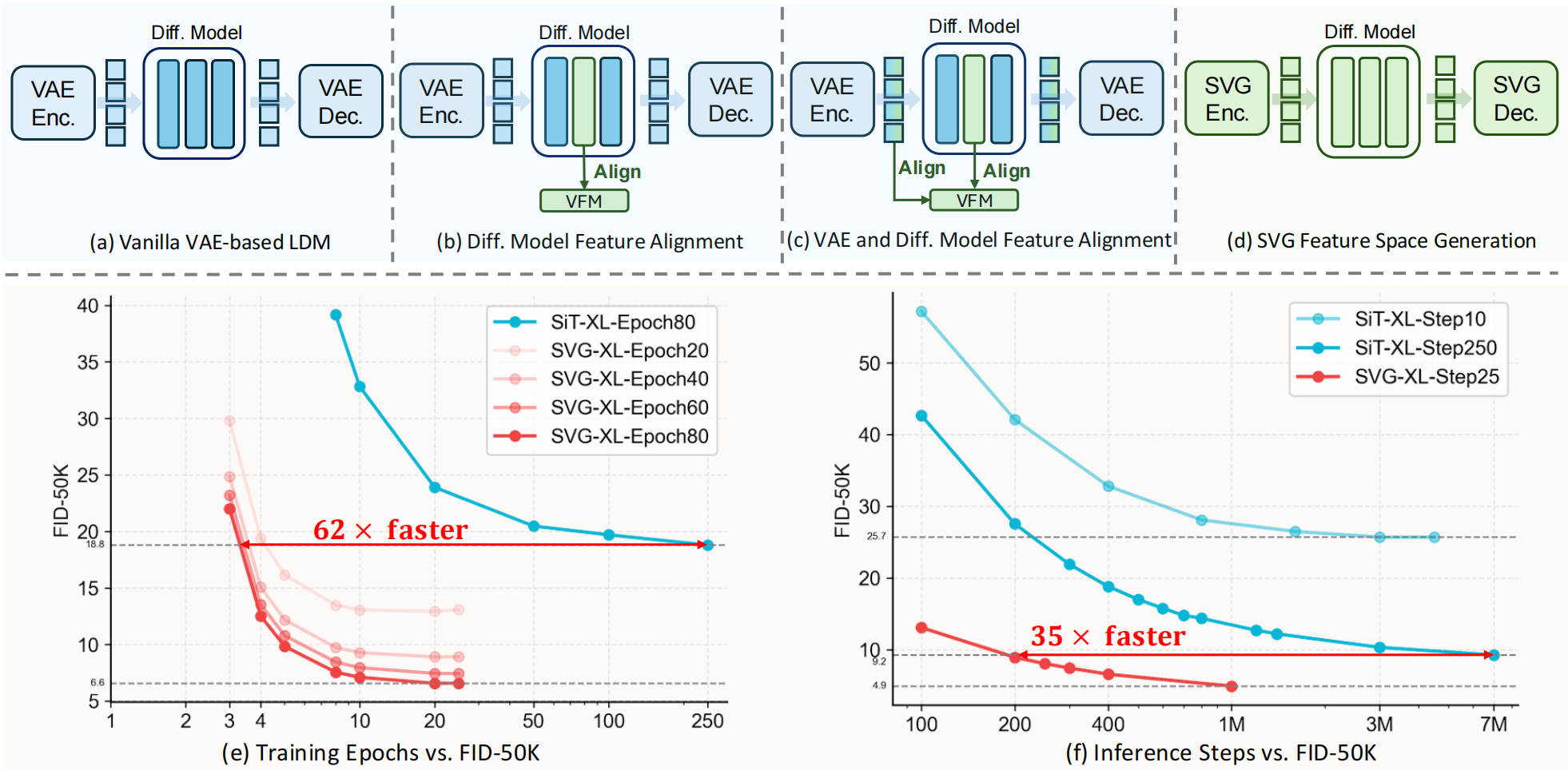
Minglei Shi*, Haolin Wang*, Wenzhao Zheng†, Ziyang Yuan, Xiaoshi Wu, Xintao Wang, Pengfei Wan, Jie Zhou, Jiwen Lu International Conference on Learning Representations (ICLR), 2026. [arXiv] [Code] [Model] [Project Page] [中文解读 (in Chinese)] SVG is a latent diffusion model without variational autoencoders to unleash Self-supervised representations for Visual Generation. |

|
Yixuan Zhu*, Jiaqi Feng*, Wenzhao Zheng†, Yuan Gao, Xin Tao, Pengfei Wan, Jie Zhou, Jiwen Lu International Conference on Learning Representations (ICLR), 2026. [arXiv] [Code] [Model] [Project Page] Astra is an interactive world model that delivers realistic long-horizon video rollouts under a wide range of scenarios and action inputs. |

|
Yifei Li, Wenzhao Zheng†, Yanran Zhang, Runze Sun, Yu Zheng, Lei Chen, Jie Zhou, Jiwen Lu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026. [arXiv] [Code] [Project Page] [Model] Skyra focuses on Grounded Artifact Reasoning to simultaneously perform Artifact Perception, Spatio-Temporal Grounding, and Explanatory Reasoning. |
|
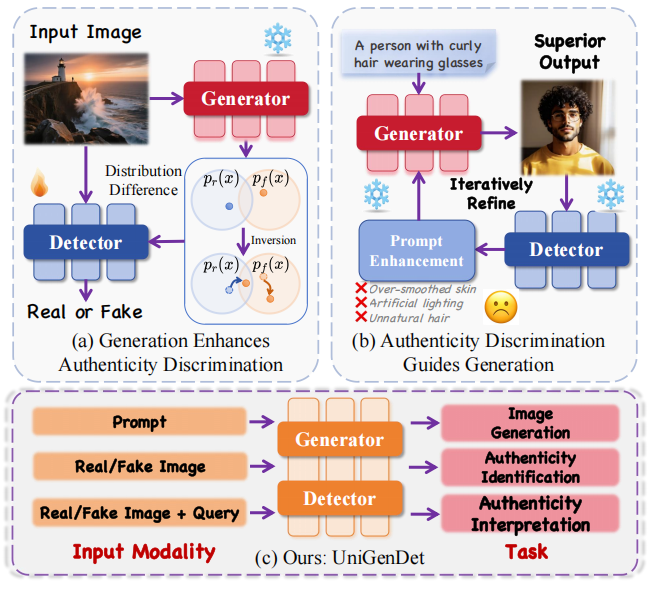
Yanran Zhang, Wenzhao Zheng†, Yifei Li, Bingyao Yu, Yu Zheng, Lei Chen, Jie Zhou, Jiwen Lu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026. [Project Page] UniGenDet bridges generation and detection in a unified, co-evolutionary framework. |
|
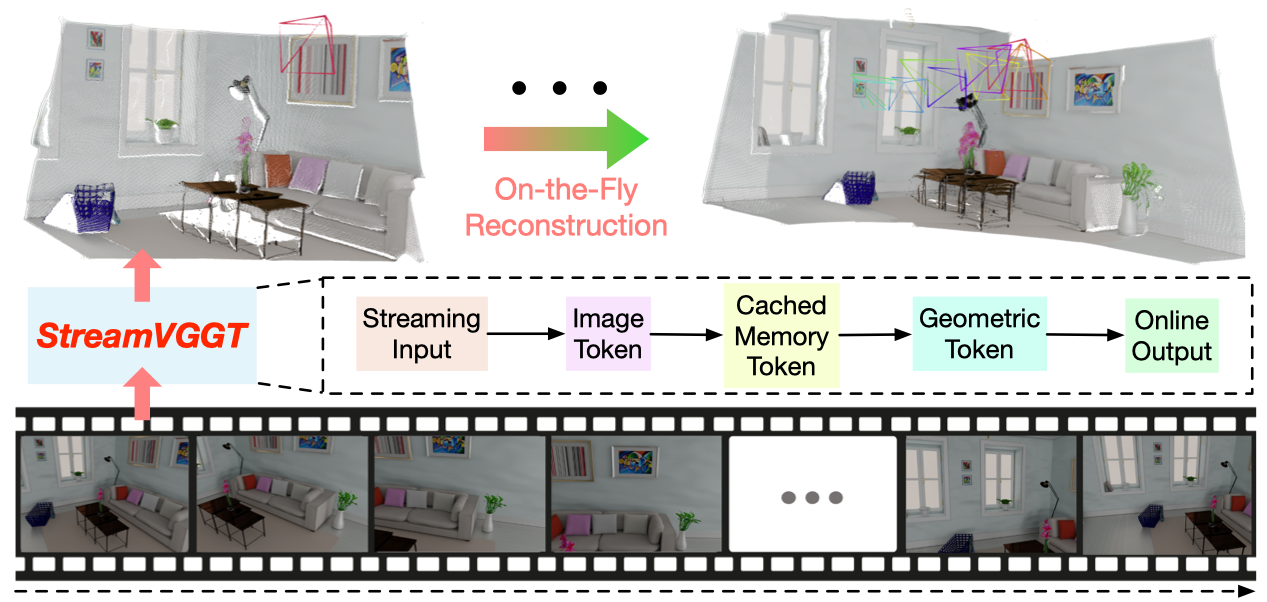
Dong Zhuo*, Wenzhao Zheng*†, Jiahe Guo, Yuqi Wu, Jie Zhou, Jiwen Lu International Conference on Learning Representations (ICLR), 2026. [arXiv] [Code] [Project Page] StreamVGGT employs temporal causal attention and leverages cached token memory to support efficient incremental on-the-fly reconstruction, enabling interative and real-time online applications. |
|
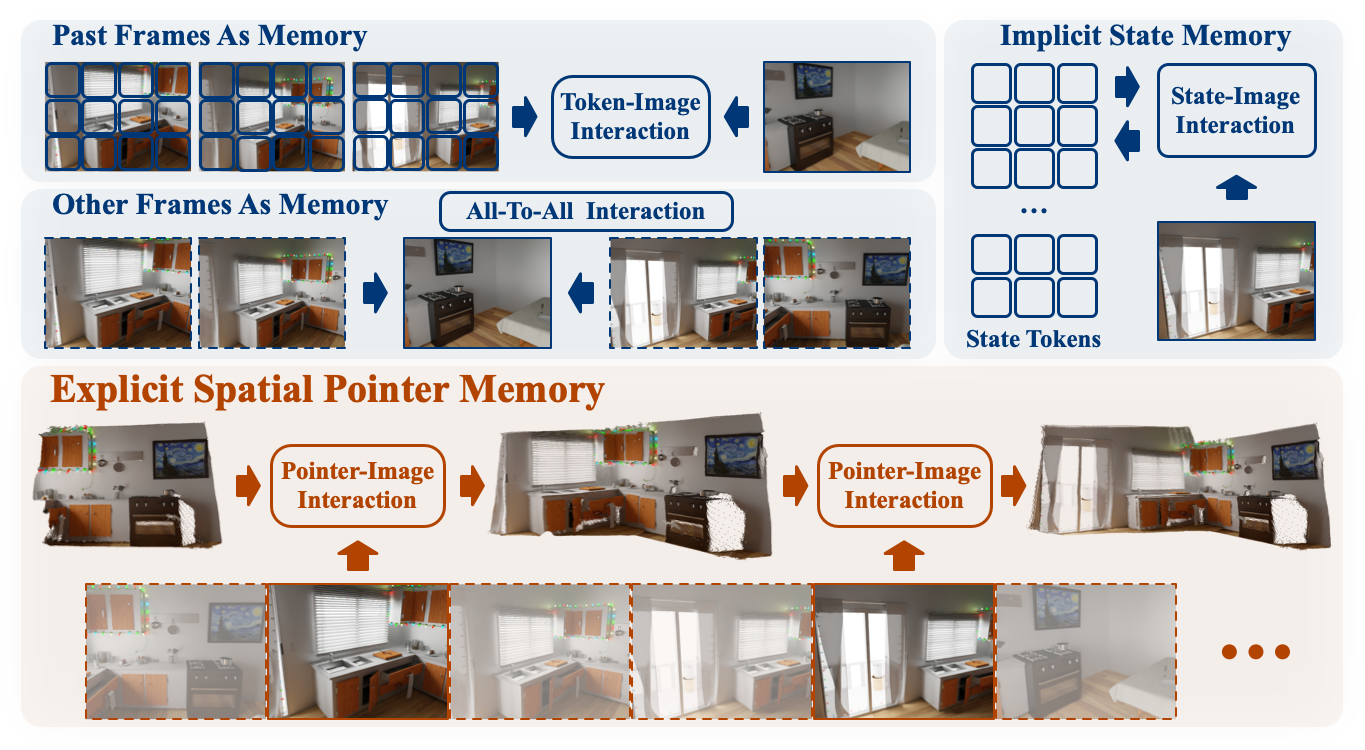
Yuqi Wu*, Wenzhao Zheng*†, Jie Zhou, Jiwen Lu Conference on Neural Information Processing Systems (NeurIPS), 2025. [arXiv] [Code] [Project Page] Point3R is an online framework for dense streaming 3D reconstruction using explicit spatial memory, which achieves competitive performance with low training costs. |

|
Nan Huang, Wenzhao Zheng, Chenfeng Xu , Kurt Keutzer , Shanghang Zhang, Angjoo Kanazawa, Qianqian Wang IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. [arXiv] [Code] [Project Page] Our model produces instance-level fine-grained moving object masks and can handle challenging scenarios including articulated structures, shadow reflections, dynamic background motion, and drastic camera movement. |

|
Yuanhui Huang* , Wenzhao Zheng*†, Yunpeng Zhang , Jie Zhou, Jiwen Lu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023. [arXiv] [Code] [Project Page] [中文解读 (in Chinese)] Given only surround-camera motorcycle RGB images barrier as inputs, our model (trained using trailer only sparse traffic cone LiDAR point supervision) can predict the semantic occupancy for all volumes in the 3D space. |

|
Sicheng Zuo*, Zixun Xie*, Wenzhao Zheng*†, Shaoqing Xu, Fang Li, Shengyin Jiang, Long Chen, Zhi-Xin Yang, Jiwen Lu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026. [arXiv] [Code] [Project Page] [中文解读 (in Chinese)] DVGT is a universal visual geometry transformer for autonomous driving, which directly predicts metric-scaled global 3D point maps from a sequence of unposed multi-view images. |
|
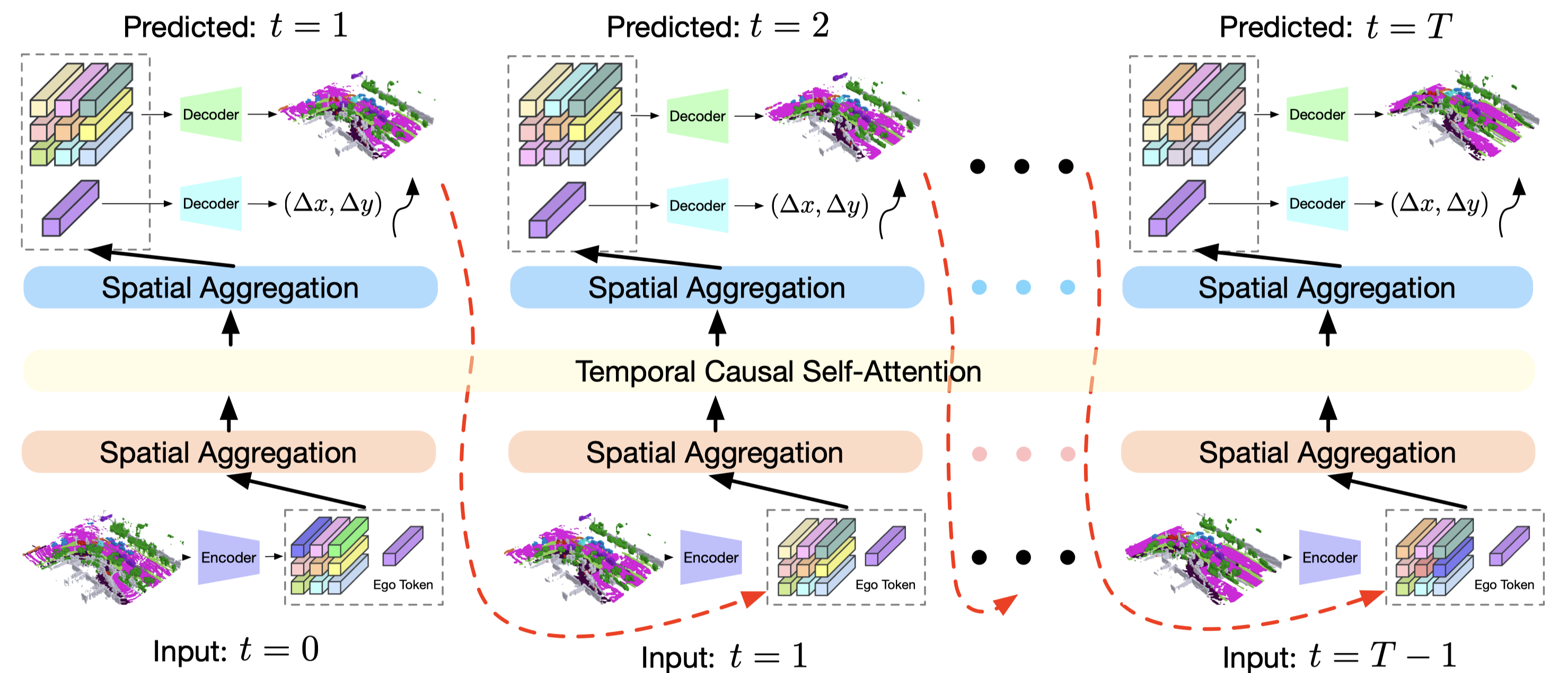
Wenzhao Zheng*†, Weiliang Chen*, Yuanhui Huang, Borui Zhang, Yueqi Duan, Jiwen Lu European Conference on Computer Vision (ECCV), 2024. [arXiv] [Code] [Project Page] [中文解读 (in Chinese)] OccWorld models the joint evolutions of 3D scenes and ego movements and paves the way for interpretable end-to-end large driving models. |
|
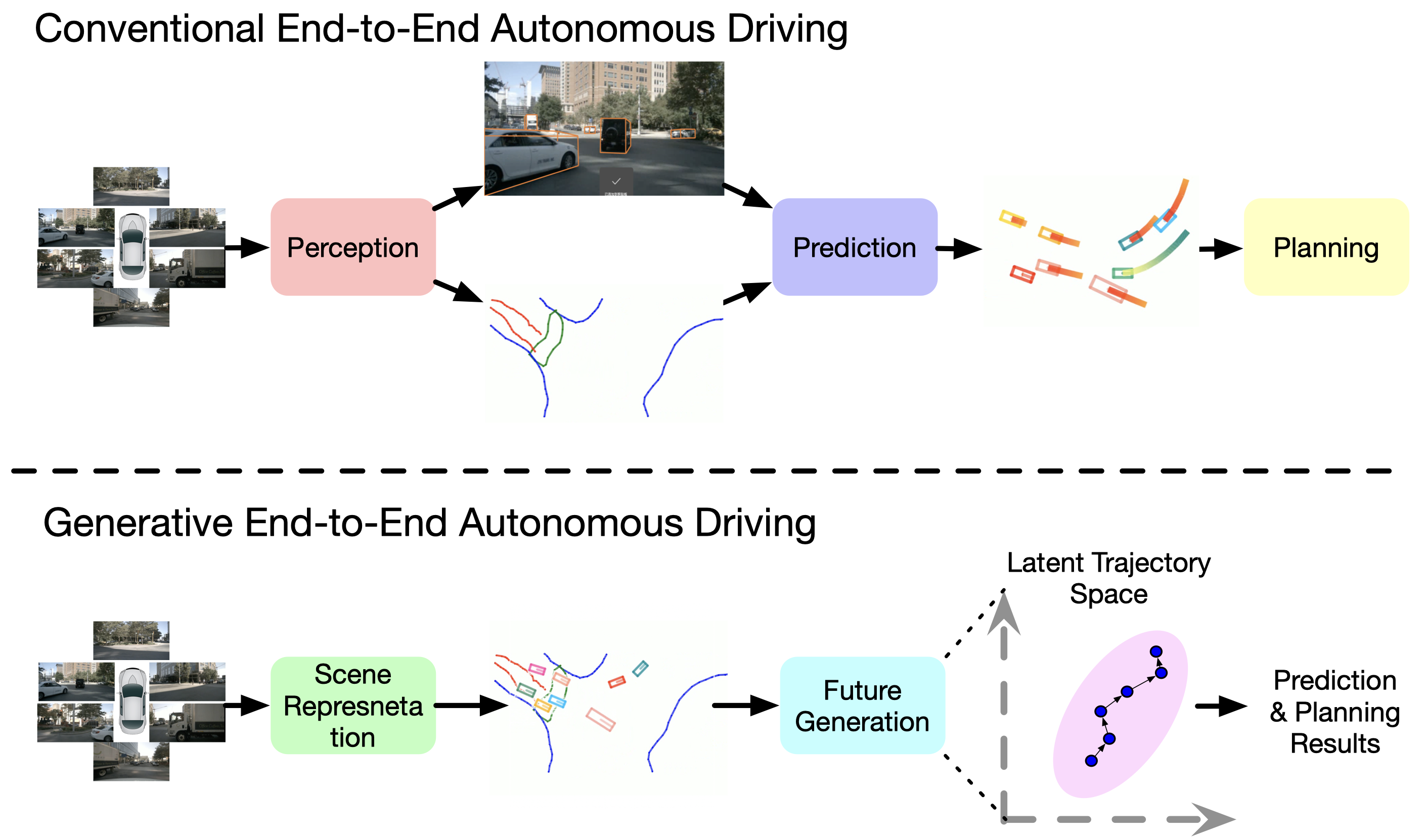
Wenzhao Zheng*, Ruiqi Song* , Xianda Guo* , Chenming Zhang , Long Chen European Conference on Computer Vision (ECCV), 2024. [arXiv] [Code] [中文解读 (in Chinese)] GenAD casts end-to-end autonomous driving as a generative modeling problem. |
|
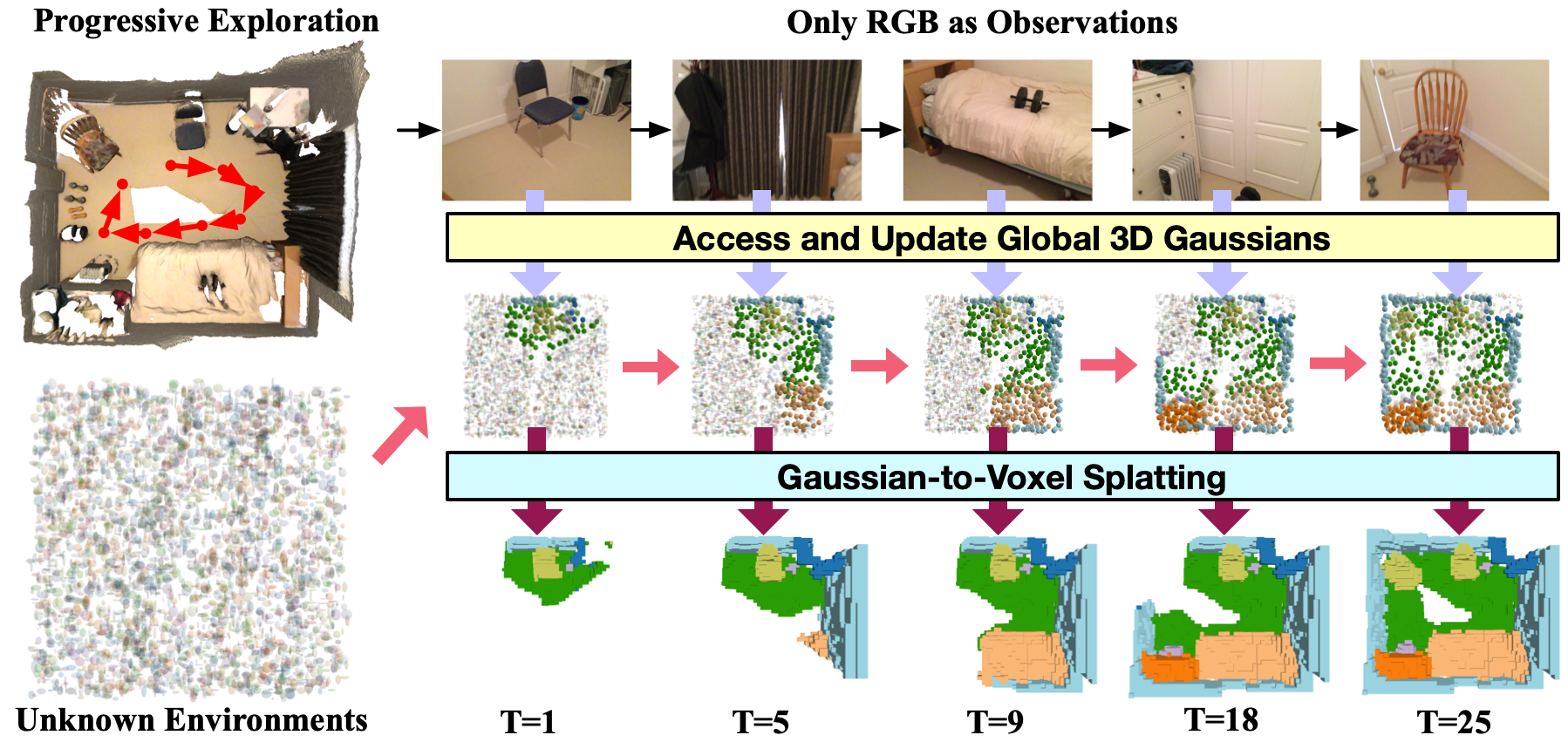
Yuqi Wu*, Wenzhao Zheng*†, Sicheng Zuo, Yuanhui Huang , Jie Zhou, Jiwen Lu IEEE International Conference on Computer Vision (ICCV), 2025. [arXiv] [Code] [Project Page] EmbodiedOcc formulates an embodied 3D occupancy prediction task and employs a Gaussian-based framework to accomplish it. |

|
Chaojun Ni*, Cheng Chen* , Xiaofeng Wang* , Zheng Zhu* , Wenzhao Zheng, Boyuan Wang, Tianrun Chen , Guosheng Zhao , Haoyun Li , Zhehao Dong, Qiang Zhang , Yun Ye , Yang Wang , Guan Huang , Wenjun Mei IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026. [arXiv] [Code] [Project Page] SwiftVLA integrates 4D spatiotemporal information into a lightweight vision-language-action model at minimal costs. |
|
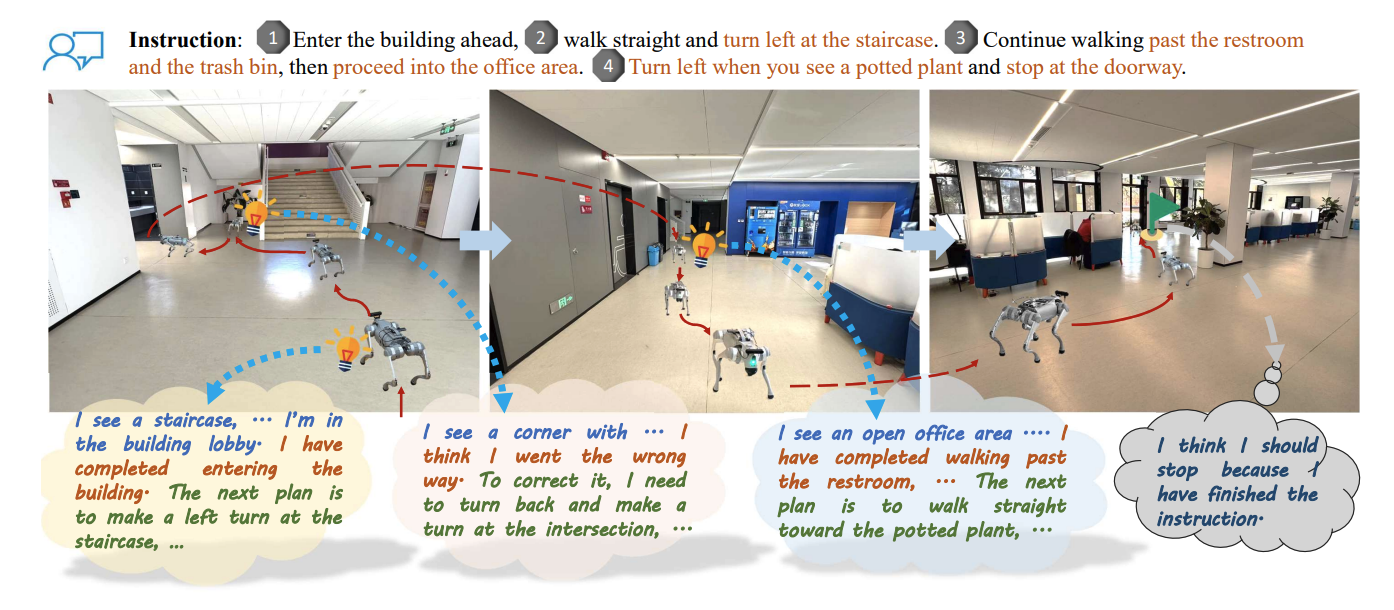
Wenxuan Guo, Xiuwei Xu, Yichen Liu, Xiangyu Li, Hang Yin, Huangxing Chen, Wenzhao Zheng, Jianjiang Feng, Jie Zhou, Jiwen Lu IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026. AwareVLN equips a VLN agent with self-aware and structured reasoning that is adaptively triggered at key navigation points. |
|
|
|
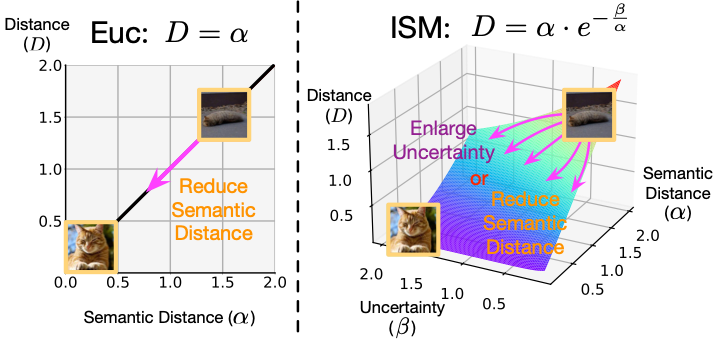
Chengkun Wang* , Wenzhao Zheng*†, Zheng Zhu, Jie Zhou, Jiwen Lu IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI, IF: 24.31), 2024. [arXiv] [Code] We propose an introspective deep metric learning (IDML) framework for uncertainty-aware comparisons of images. |
|
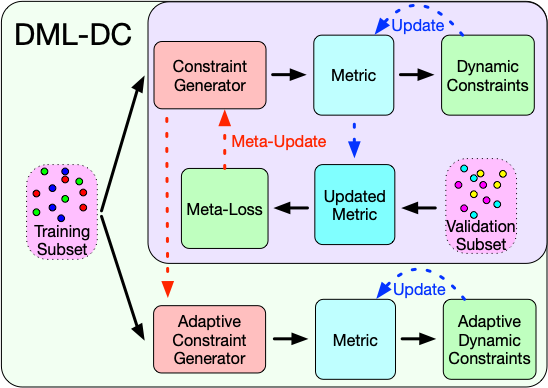
Wenzhao Zheng, Jiwen Lu, Jie Zhou IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI, IF: 24.31), 2023. [PDF] This paper formulates deep metric learning under a unified framework and propose a dynamic constraint generator to produce adaptive composite constraints to train the metric towards good generalization. |
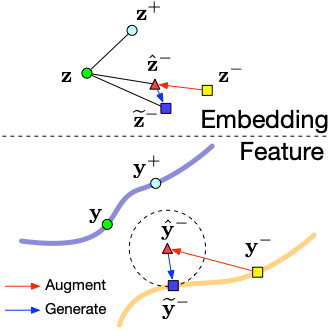
|
Wenzhao Zheng, Zhaodong Chen , Jiwen Lu, Jie Zhou IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019 (oral). Wenzhao Zheng, Jiwen Lu, Jie Zhou IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI, IF: 24.31), 2021. [PDF] [PDF] (Journal version) [Code] We perform linear interpolation on embeddings to adaptively manipulate their hardness levels and generate corresponding label-preserving synthetics for recycled training. |
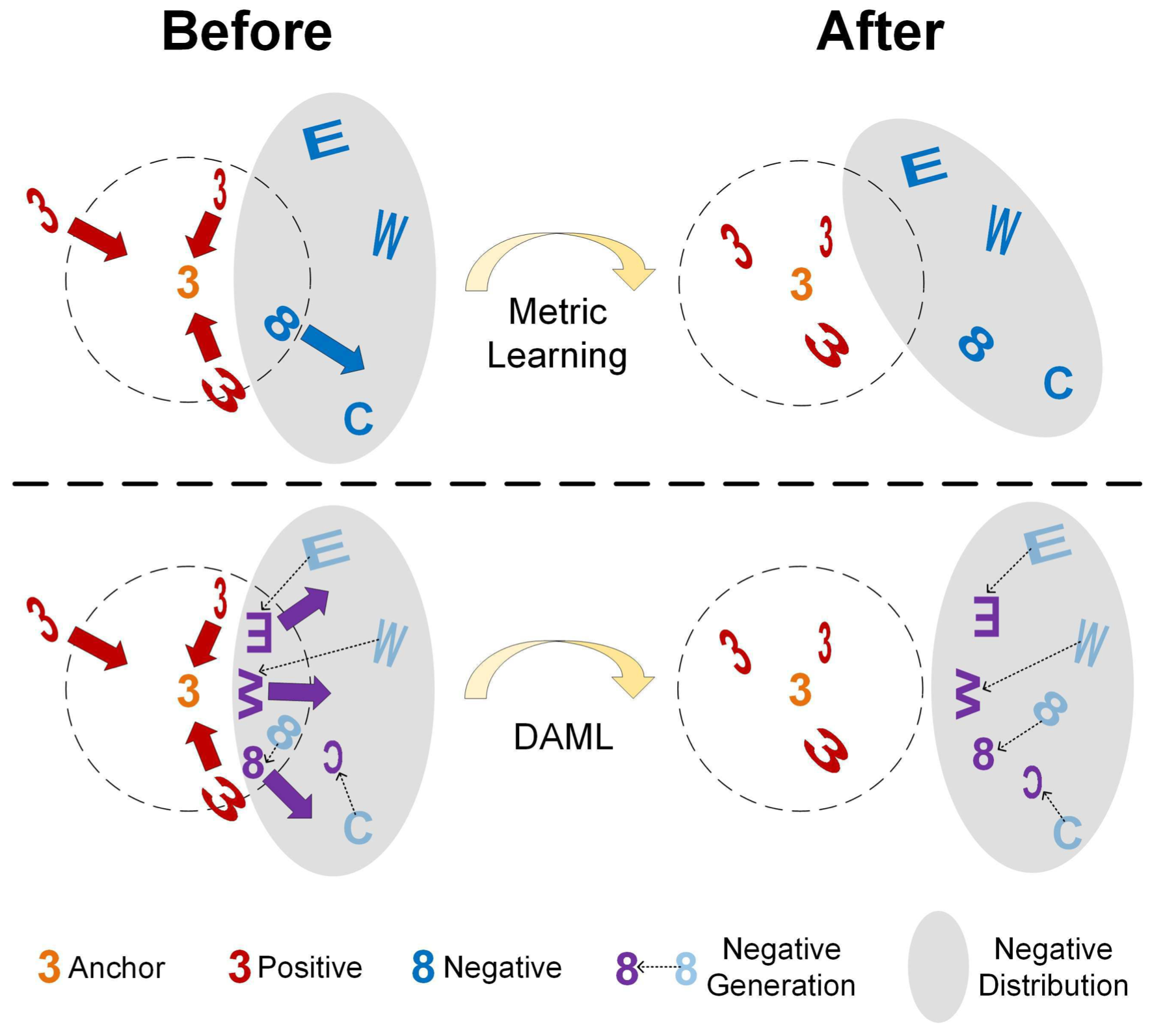
|
Yueqi Duan, Wenzhao Zheng, Xudong Lin , Jiwen Lu, Jie Zhou IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018 (spotlight). Yueqi Duan, Jiwen Lu, Wenzhao Zheng, Jie Zhou IEEE Transactions on Image Processing (T-IP, IF: 11.041), 2020. [PDF] [PDF] (Journal version) [Code] We generate potential hard negatives adversarial to the learned metric as complements. |
|
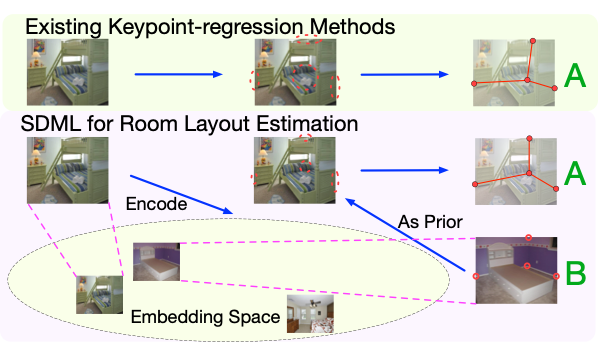
Wenzhao Zheng, Jiwen Lu Jie Zhou European Conference on Computer Vision (ECCV), 2020. [PDF] We are the first to apply deep metric learning to prediction tasks with structured labels. |
|
|
|
|
|
|